14. Managing Growth
In the course of everyday operations, your GemStone/S 64 Bit repository will grow. Some of this growth will be the result of new data in your repository, but some will represent unreferenced or outdated objects. These objects, no longer needed, must be removed to prevent the repository from growing arbitrarily large. The process of removing unwanted objects to reclaim their storage is referred to as garbage collection.
This chapter describes GemStone’s garbage collection mechanisms and explains how and when to use them.
This chapter discusses the following topics:
Garbage Collection Operations
This include MarkForCollection, Epoch Garbage Collection, and Reclaim.
14.1 Basic Concepts
Smalltalk execution can produce a number of objects needed only for the moment. In addition, normal business operations can cause previously committed objects to become obsolete. To make the best use of system resources, it is desirable to reclaim the resources these objects use as soon as possible.
Different Types of Garbage
Garbage collection mechanisms vary according to where garbage collection occurs — temporary (scratch) memory or permanent object space — and how it occurs — automatically, or in response to an administrator’s action.
Each Gem session has its own private memory intended for scratch space, known as local object memory. The Gem session uses local object memory for a variety of temporary objects, which can be garbage-collected individually. This type of garbage collection is handled automatically by the session and is (for the most part) not configurable, although memory can be configured for specific gem requirements. These issues are covered in Chapter 13, “Managing Memory”.
Permanent objects are organized in units of 16 KB called pages. Pages exist in the Gem’s private page cache, the Stone repository monitor’s private page cache, the shared page cache, and on disk in the extents. When first created, each page is associated with a specific transaction; after its transaction has completed, GemStone does not write to that page again until all its storage can be reclaimed.
Objects on pages are not garbage-collected individually. Instead, the presence of a shadow object or dead object triggers reclaim of the page on which the object resides. Live objects on this page are copied to another page.
The Process of Garbage Collection
Removing unwanted objects is a two-phase process:
1. Identify—mark—superfluous objects.
2. Reclaim the resources they consume.
Together, marking and reclaiming unwanted objects is collecting garbage.
Complications ensue because each Gem in a transaction is guaranteed a consistent view of the repository: all visible objects are guaranteed to remain in the same state as when the transaction began. If another Gem commits a change to a mutually visible object, both states of the object must somehow coexist until the older transaction commits or aborts, refreshing its view. Therefore, resources can be reclaimed only after all transactions concurrent with marking have committed or aborted.
Older views of committed, modified objects are called shadow objects.
Live objects
GemStone considers an object live if it can be reached by traversing a path from AllUsers, the root object of the GemStone repository. By definition, AllUsers contains a reference to each user’s UserProfile. Each UserProfile contains a reference to the symbol list for a given user, and those symbol dictionaries in these lists in turn point to classes and instances created by that user’s applications. Thus, AllUsers is the root node of a tree whose branches and leaves encompass all the objects that the repository requires at a given time to function as expected.
Transitive closure
Traversing such a path from a root object to all its branches and leaves is called transitive closure.
Dead objects
An object is dead if it cannot be reached from the AllUsers root object. Other dead objects may refer to it, but no live object does. Without living references, the object is visible only to the system, and is a candidate for reclaim of both its storage and its OOP.
Shadow objects
A shadow object is a committed object with an outdated value. A committed object becomes shadowed when it is modified during a transaction. Unlike a dead object, a shadow object is still referenced in the repository because the old and new values share a single object identifier.The shadow object must be maintained as long as it is visible to other transactions on the system; then the system can reclaim only its storage, not its OOP (which is still in use identifying the committed object with its current value).
Commit records
Views of the repository are based on commit records, structures written when a transaction is committed. Commit records detail every object modified (the write set), as well as the new values of modified objects. The Stone maintains these commit records; when a Gem begins a transaction or refreshes its view of the repository, its view is based on the most recent commit record available.
Each session’s view is based on exactly one commit record at a time, but any number of sessions’ views can be based on the same commit record.
NOTE
The repository must retain each commit record and the shadow objects to which it refers as long as that commit record defines the transaction view of any session.
Commit record backlog
The list of commit records that the Stone maintains in order to support multiple repository views is the commit record backlog.
Shadow or Dead?
The following example illustrates the difference between dead and shadow objects. In Figure 14.1, a user creates a SymbolAssociation in the SymbolDictionary Published. The SymbolAssociation is an object (oop 27111425) that refers to two other objects, its instance variables key (#City, oop 20945153), and value ('Beaverton', oop 27110657).
The Topaz command “display oops” causes Topaz to display within brackets ( [ ] ) the identifier, size, and class of each object. This display is helpful in examining the initial SymbolAssociation and the changes that occur.
Figure 14.1 An Association Is Created and Committed

topaz 1> display oops
topaz 1> printit
Published at: #City put: 'Beaverton'.
Published associationAt: #City
%
[27111425 sz:2 cls: 111617 SymbolAssociation] a SymbolAssociation
key [20945153 sz:4 cls: 110849 Symbol] City
value [27110657 sz:9 cls: 74753 String]
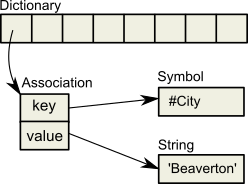
Figure 14.2 shows a second Topaz session that logs in at this point. Notice that the Topaz prompt identifies the session by displaying a digit. Because Session 1 committed the SymbolAssociation to the repository, Session 2 can see the SymbolAssociation.
Figure 14.2 A Second Session Can See the Association
topaz 2> display oops
topaz 2> printit
Published associationAt: #City.
%
[27111425 sz:2 cls: 111617 SymbolAssociation] a SymbolAssociation
key [20945153 sz:4 cls: 110849 Symbol] City
value [27110657 sz:9 cls: 74753 String] Beaverton
Now Session 1 changes the value instance variable, creating a new SymbolAssociation (Figure 14.3). Notice in the oops display that the new SymbolAssociation object has the same identifier (27111425) as the previous Association.
Figure 14.3 The Value Is Replaced, Changing the Association
topaz 1> printit
City := 'Portland'.
Published associationAt: #City.
%
[27111425 sz:2 cls: 111617 SymbolAssociation] a SymbolAssociation
key [20945153 sz:4 cls: 110849 Symbol] City
value [27109121 sz:8 cls: 74753 String] Portland
topaz 1> commit
Successful commit
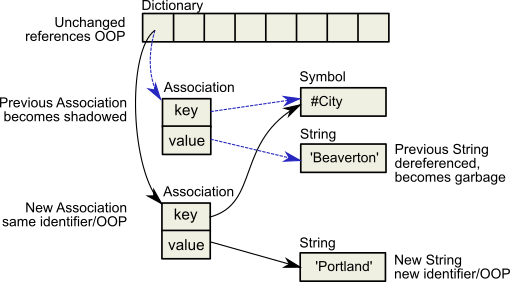
- The SymbolAssociation is now shadowed. Because the shadow SymbolAssociation was part of the committed repository and is still visible to other transactions (such as that of Session 2), it cannot be overwritten. Instead, the new SymbolAssociation is written to another page, one allocated for the current transaction.
- The previous value (oop 27110657) is no longer referenced in the repository. For now, this object is considered possibly dead; we cannot be sure it is dead because, although the object has been dereferenced by a committed transaction, other, concurrent transactions might have created a reference to it.
Even though Session 1 committed the change, Session 2 continues to see the original SymbolAssociation and its value (Figure 14.4). Session 2 (and any other concurrent sessions) will not see the new SymbolAssociation and value until it either commits or aborts the transaction that was ongoing when Session 1 committed the change.
Figure 14.4 Session 2 Sees Change After Renewing Transaction View of Repository
topaz 2> printit
Published associationAt: #City.
%
[27111425 sz:2 cls: 111617 SymbolAssociation] a SymbolAssociation
key [20945153 sz:4 cls: 110849 Symbol] City
value [27110657 sz:9 cls: 74753 String] Beaverton
topaz 2> abort
topaz 2> printit
Published associationAt: #City.
%
[27111425 sz:2 cls: 111617 SymbolAssociation] a SymbolAssociation
key [20945153 sz:4 cls: 110849 Symbol] City
value [27109121 sz:8 cls: 74753 String] Portland
Only when all sessions with concurrent transactions have committed or aborted can the shadow object be garbage collected.
What Happens to Garbage?
This section describes the steps involved in garbage collection. Specific garbage collection mechanisms will follow these steps, although the details will vary when using different garbage collection mechanisms.
The basic garbage collection process encompasses nine steps:
1. Find all the live objects in the system by traversing references, starting at the system root AllUsers. This step is called mark/sweep.
2. The Gem that performed mark/sweep now has a list of all live objects. It also knows the universe of all possible objects: objects whose OOPs range from zero to the highest OOP in the system. It can now compute the set of possible dead objects as follows:
a. Subtract the live objects from the universe of possible objects.
b. Subtract all the unassigned (free) OOPs in that range.
This step is called the object table sweep because the Gem uses the object table to determine the universe of possible objects and the unassigned OOPs.
3. The Gem performing this work now has a list of possibly dead objects. We can’t be sure they’re dead because, during the time that the mark/sweep and object table sweep were occurring, other concurrent transactions might have created references to some of them.
The Gem sends the Stone the possible dead set and returns.
4. Now, in a step called voting, each Gem logged into the system must search its private memory to see if it has created any references to objects in the possible dead set. When it next commits or aborts, it votes on every object in the possible dead set. Objects referenced by a Gem are removed from the possible dead set.
NOTE
Gems do not vote until they complete their current transaction. If a Gem is sleeping or otherwise engaged in a long transaction, the vote cannot be finalized and garbage collection pauses at this point. Commit records accumulate, garbage accumulates, and a variety of problems can ensue.
5. Because all the previous steps take time, it’s possible that some Gems were on the system when the mark/sweep began, created a reference to an object now in the possible dead set, and then logged out. They cannot vote on the possible dead set, but objects they’ve modified are in the write sets of their commit records. The Admin Gem, a process dedicated to administrative garbage collection tasks, scans all these write sets (the write set union), and votes on their behalf. This is called the write set union sweep.
6. After all voting is complete, the resulting set now holds nothing but unreferenced objects. The Stone now promotes the objects from possibly dead to dead.
7. the Reclaim Gem reclaims pages: it copies live objects on the page onto a new page, thereby compacting live objects in page space. The page now contains only recycleable objects and perhaps free space.
8. The Reclaim Gem commits. The reclaimed OOPs are returned to their free pool.
9. The Reclaim Gem’s commit record is disposed of. The reclaimed pages are returned to their free pool.
Admin and Reclaim Gems
It is useful to understand the distinction between the Admin Gem and the Reclaim Gem:
- The Admin Gem finalizes the vote on possibly dead objects (Step 5), and performs the write set union sweep. The Admin Gem also performs Epoch Garbage Collection, if enabled.
- The Reclaim Gem is dedicated to the task of reclaiming shadowed pages and dead objects repository-wide, along with their OOPs.
The Reclaim Gem includes a master session and multiple reclaim sessions, each being a thread within the Reclaim Gem process. This allows reclaim to occur in parallel.
By default, the Admin Gem and the Reclaim Gem with one reclaim session are configured to run, and are started automatically when the Stone is started. By default, epoch is disabled.
- We recommend that you leave the Admin Gem running at all times, although it is required only following a markForCollection or markGcCandidatesFromFile:, or after a epoch garbage collection operation. (Subsequent sections of this chapter describe these operations in detail.) If the Admin Gem is not running following one of these operations, the garbage collection process cannot complete, and garbage can build up in your system.
- We recommend that you have the Reclaim Gem running at all times, to reclaim shadow objects.
Admin and Reclaim Gem configuration parameters
Both the Admin and Reclaim Gems are run from the GcUser account, a special account that logs in to the repository to perform garbage collection tasks. This account is used to set configuration values for the GcGems.
The configuration parameters that apply to either the Admin or Reclaim Gems can either be set persistently, or at runtime.
To modify configuration parameters persistently, log in as GcUser (GcUser’s initial password is ‘swordfish’, as is DataCurator’s and SystemUser’s) and send the message at:aKey put:aValue to UserGlobals.
For example, to set #reclaimMinPages to 100:
topaz> set user GcUser password thePassword
login
...
topaz 1> printit
UserGlobals at: #reclaimMinPages put: 100.
System commitTransaction
%
To set parameters at runtime, you do not need to log in as GcUser or perform a commit. A user with GarbageCollection privilege, such as DataCurator, can execute System class methods setReclaimConfig:toValue: or setAdminConfig:toValue:.
topaz> set user DataCurator password thePassword
login
...
topaz 1> printit
System setReclaimConfig: #reclaimMinPages toValue: 100.
%
Specific configuration parameters and how to apply them are discussed in detail later in this chapter.
GemStone’s Garbage Collection Mechanisms
GemStone provides the following mechanisms that together mark and reclaim garbage, thereby helping you to control repository growth.
Marking
Repository-wide marking — To prevent the repository from growing large enough to cause problems on a regular basis, you can run Repository >> markForCollection. This method combines a full sweep of all objects in the repository and the marking of each possible dead object in a single operation.
Epoch garbage collection — If enabled, the Admin Gem periodically examines all transactions written since a specific, recent time (the beginning of this epoch) for objects that were created and then dereferenced during that period. However, epoch garbage collection cannot reclaim objects that are created in one epoch but dereferenced in another. In spite of its name, epoch garbage collection only marks; it does not reclaim. You can configure various aspects to maximize its usefulness. Epoch garbage collection is disabled by default. For details about epoch garbage collection, see Epoch Garbage Collection.
Reclaiming
Reclaim — Once you’ve run markForCollection or epoch garbage collection, the Reclaim Gem will reclaim pages that contain either dead or shadow objects. When there are a high number of objects needing to be reclaimed, you may increase the number of sessions under the Reclaim Gem. For details about reclaiming pages, see Reclaim.
GcLock
Many garbage collection process, such as mark/sweep operations, should not be run concurrently. To prevent this, there is a shared internal lock called the GcLock. Garbage collection processes that cannot run concurrently, such as markForCollection, get the GcLock, which prevents another one from starting up. The GcLock is also held by the Admin Gem at certain periods.
In addition to garbage collection, some repository-wide operations such as GsObjectInventory (Profiling Repository Contents) also hold the GcLock while they are running.
If another task that requires the GcLock is in progress at the time you try to do markForCollection or findDisconnectedObjects..., they will not execute, but report an error similar to that shown below.
-- Request for MFC gclock by session 10 denied, reason: vote state
is voting, sessionId not voted 2
ERROR 2501 , a Error occurred (error 2501), Request for gcLock
timed out.
'Request for MFC gclock by session 10 denied, reason: vote state
is voting, sessionId not voted 2' (Error)
The cause of the conflict may be:
- Another operation that requires the GcLock is in progress in another session; this includes epoch and MFC, and also operations such as GsObjectInventory.
- A previous epoch or markForCollection completed the mark phase, but voting on possibly dead objects has not completed.
For voting to complete, the Admin Gem must be running. Also, any long-running session that neither aborts nor commits will prevent the vote from completing.
Symbol Garbage Collection
Symbols in GemStone are a special case of Object, since they must always have a unique OOP across all sessions. To ensure this, symbol creation is managed by the SymbolUser, who creates all new Symbols. Symbols are stored in the AllSymbols dictionary, and are not removed, to avoid any risk of creating duplicate symbols.
However, there are cases where a large number of unimportant symbols are created, perhaps inadvertently. To reclaim this space and to manage the size of AllSymbols, you can configure GemStone to collect unreferenced symbols in a multi-step process that ensures that symbols in use are not collected.
By default, Symbol garbage collection is not enabled. It can be enabled using the configuration parameter, STN_SYMBOL_GC_ENABLED, or by the runtime equivalent, #StnSymbolGcEnabled. If enabled, symbol garbage collection is performed automatically in the background and requires no management.
When enabled, unused symbols are located and put in a possibleDeadSymbols collection as part of a markForCollection,. These symbols are hidden, to remove references from AllSymbols but retain the OOPs until the voting, union, and finalization is done. Any lookups on the hidden symbol will return the existing hidden symbol and restore it to the AllSymbols dictionary.
Once voting and write-set union sweep are done, the symbols that are otherwise unreferenced are removed from the possibleDeadSymbols, so they will be collected by the next markForCollection.
14.2 MarkForCollection
Privileges required: GarbageCollection.
The method Repository>>markForCollection sweeps the entire repository and marks as live all objects that can be reached through a transitive closure on the symbol lists in AllUsers, as described on here. The remaining objects become the list of possible dead objects.
markForCollection only provides a set of possible dead objects for voting and eventual reclaiming as described under What Happens to Garbage?. It does not reclaim the space or OOPs itself; the Reclaim Gem does that, as described under Reclaim.
To mark unreferenced GemStone objects for collection, log in to GemStone and send your repository the message markForCollection, as in the following example:
topaz 1> printit
SystemRepository markForCollection
%
If you are performing markForCollection on a large production repository, consider the steps described under Impact on Other Sessions.
This method aborts the current transaction and runs markForCollection inside a transaction, but monitors the commit record backlog so it can abort as necessary to prevent the backlog from growing. When markForCollection completes, the session reenters a transaction, if it was in one when this method was invoked.
When markForCollection completes successfully, the Gem that started it displays a message such as the one below:
Warning: a Warning occurred (notification 2515), markForCollection
found 110917 live objects, 3496 dead objects(occupying approx
314640 bytes)
If another garbage collection task is in progress at the time you try to do markForCollection, this method will retry for a fixed period, reporting status. If the other operation does not complete within the timeout period, it reports an error indicating it could not get the GcLock. See GcLock for more details.
Before issuing the error, the markForCollection method waits up to a minute for the other operation to complete. To have the markForCollection wait for a longer period, use markForCollectionWait: waitTimeSeconds. To wait as long as necessary for the other garbage collection to finish, pass the argument –1. Do so with caution, however; under certain conditions, the session could wait forever. To avoid this:
- Make sure that other sessions are committing or aborting, which allows voting on possible dead to complete.
- Make sure that the Admin Gem is running to complete processing of dead objects once the vote is completed.
Impact on Other Sessions
The markForCollection operation uses multi-threaded scan. For more details on this, see Multi-Threaded Scan.
By default, markForCollection limits is use of cpu resources if the cpu load on the system reaches 90%. It starts the operation with two threads and a page buffer size of 128. If the cpu limit is reached, the code automatically causes threads to sleep until the load is less than 90%. Depending upon the I/O required, the system may never reach this limit.
To enable markForCollection to complete as quickly as possible, you can use:
SystemRepository fastMarkForCollection
This uses higher settings (95% of CPU, and a number of threads based on the current hardware) to use as many system resources as possible. The performance of anything else running on the same system may be heavily degraded.
For maximum control, use the method
SystemRepository markForCollectionWithMaxThreads: threadsCt
waitForLock: seconds
pageBufSize: pageBufSize
percentCpuActiveLimit: percentLimit
This allows you to specify the precise limits.
Starting markForCollection with these limits provides a specification for the trade-off you wish to make between speed to complete and the impact on other sessions. The desired trade-off may vary over time; for example, if your markForCollection extends over both business hours and non-business hours, you may accept greater impact during these periods of light load. The Multi-threaded scan parameters can be changed at runtime, as described under Tuning Multi-Threaded Scan.
After the markForCollection has completed, there may be additional impact on other sessions, since it is likely that dead objects that require reclaim were identified. After the remaining Garbage Collection steps have completed, the Reclaim Gem Sessions may become busy reclaiming the dead objects.
Scheduling markForCollection
To invoke markForCollection using the cron facility, create a three-line script file similar to the Topaz example here by entering everything except the prompt. Use this script as standard input to topaz, and redirect the standard output to another file:
topaz < scriptName > logName
Make sure that $GEMSTONE and any other required environment variables are defined during the cron job. Either create a .topazini file for a user who has GarbageCollection privilege, or insert those login settings at the beginning of the script. For information about using cron, refer to your operating system documentation.
14.3 Epoch Garbage Collection
Privileges required: GarbageCollection.
Epoch garbage collection operates on a finite set of recent transactions: the epoch. Using the write set that the Stone maintains for each transaction, the Admin Gem examines every object created during the epoch. If an object is unreferenced by the end of the epoch, it is marked as garbage and added to the list of possible dead objects.
Epoch collection is efficient because:
- It’s faster and easier to perform a transitive closure on a few recent transactions than on the entire repository.
- Most objects die young, especially in applications characterized by numerous small transactions updating a few previously committed objects. An epoch of the right length can collect most garbage automatically.
Although epoch collection identifies a lot of dead objects, it cannot replace markForCollection because it will never detect objects created in one epoch and dereferenced in another.
By default, epoch garbage collection is disabled. You can enable it in either of two ways:
- Before you start the Stone, set the STN_EPOCH_GC_ENABLED configuration option to TRUE.
- Execute the method System class>>enableEpochGc. You may also manually disable epoch garbage collection using System class>>disableEpochGc. Using these methods updates the system configuration file.
After your installation has been operating for a while, and you’ve had the chance to collect operational statistics, consider this: epochs of the wrong length can be notably inefficient. The section Determining the Epoch Length includes an in-depth discussion of the performance trade-offs of short or long epochs
Running Epoch Garbage Collection
When epoch garbage collection is enabled, it will run automatically according to the GcUser configuration parameters #epochGcTimeLimit and #epochGcTransLimit.
You can force an epoch garbage collection to begin using System class >> forceEpochGc. forceEpochGc will return false, and not start an epoch garbage collection, if any of the following are true:
- Checkpoints are suspended.
- Another garbage collection operation is in progress.
- Unfinalized possible dead objects exist (that is, System voteState returns a non-zero value).
- The system is in restore mode.
- The Admin Gem is not running.
- Epoch garbage collection is disabled (that is, STN_EPOCH_GC_ENABLED = FALSE).
- The system is performing a reclaimAll.
- A previous forceEpochGc operation was performed and the epoch has not yet started or completed.
Tuning Epoch
Epoch Configuration Parameters
The following configuration parameters are available to control the performance of epoch garbage collection, and are stored in GcUser’s UserGlobals.For details on modifying values, see here.
Epoch garbage collection uses the multi-threaded scan (see Multi-Threaded Scan) and can be tuned to complete more quickly with more system performance and resources impact, or take longer and use fewer system resources. The parameters #epochGcPercentCpuActiveLimit, #epochGcPageBufferSize, and #epochGcMaxThreads are used to tune epoch garbage collection’s multi-threaded scan impact.
Determining the Epoch Length
Epoch garbage collection’s ability to identify unreferenced objects depends on the relationship between three variables:
- The rate of production R of short-lived objects.
- The lifetime L of these objects.
- The epoch length E.
The only variable under your direct control is epoch length. Although you cannot specify it explicitly, the following configuration parameters jointly control the length of an epoch:
Epoch garbage collection occurs when:
(the time since last epoch > epochGcTimeLimit ) AND
(transactions since last epoch > epochGcTransLimit)
The following discussion assumes that the epoch is determined by the minimum time interval (#epochGcTimeLimit) because other threshold is always met.
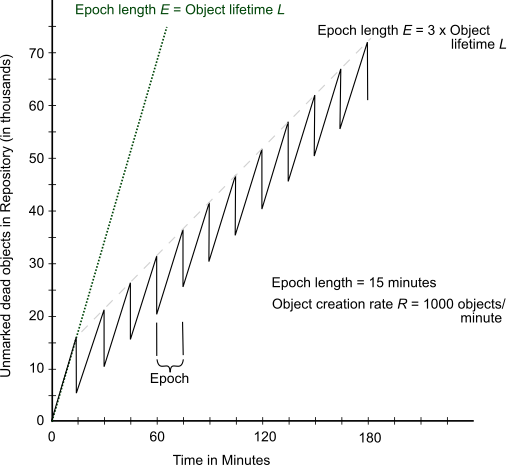
Figure 14.5 shows the effect of the epoch on the number of items marked. If L = E, for example, five minutes, every object’s lifetime spans epochs (top part of graph), and none are collected.
When the epoch is longer than an average object’s lifetime, however, some objects live and die within the same epoch, and can be marked. The lower part of Figure 14.5 shows an example where E = 3L and objects are created at a uniform rate. Objects created during the first two-thirds of the interval die before its end and are marked. Only those created during the final third survive to the next epoch.
The results shown in Figure 14.5 can be expressed as:
Objects Missed by EpochGC = R x L
Objects Recovered by EpochGC = R(E – L)
For example, assume R = 1000 objects per minute, L = 5 minutes, and E = 15 minutes. Then, for each epoch:
Objects Missed = 1000 x 5 = 5000
Objects Recovered = 1000 (15 – 5) = 10000
Figure 14.5 Effect of Collection Interval on Epoch Garbage Collection

Figure 14.6 graphs the effect of the epoch. When E = L, epoch garbage collection is in effect disabled; all objects survive into the next epoch; the number of unmarked yet dead objects in the repository grows at the creation rate. These dead objects remain unidentified until you run markForCollection.
When the epoch is extended so that E = 3L, each epoch garbage collection marks those objects both created and dereferenced during that interval. This ratio causes the sawtooth pattern in the graph. If the creation rate is uniform, two-thirds of the dead objects are marked ((E-L)/E), and one-third are missed (L/E). Consequently, the repository grows at one-third the rate of the case E = L.
This configuration trades short bursts of epoch garbage collection activity for:
Figure 14.6 Repository Growth with Short Epoch
Suppose we extend the epoch to E = 12L. The result is shown in Figure 14.7, superimposed on part of the previous figure.
Figure 14.7 Effect of Longer Epoch on Repository Growth
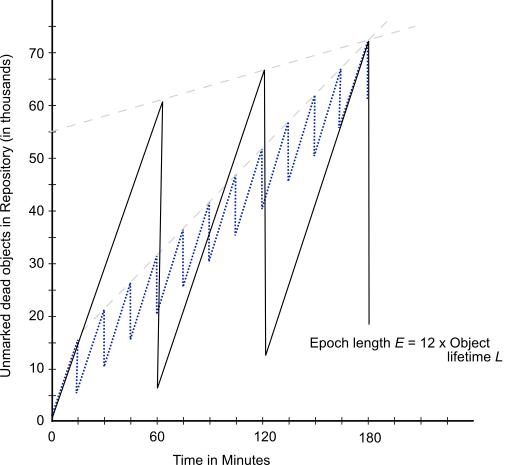
Although the longer epoch allows many more dead objects to accumulate, the growth rate of the repository is substantially less—25% of the previous case.
This configuration trades a slower growth rate for:
Certain cases have needed an epoch as long as several hours, or even a day.
Cache Statistics
Several cache statistics include information about the epoch garbage collection process. These are visible by using statmonitor data viewed in VSD (the visual statistics display tool). You may also access methods in System to get the values programmatically; see Programmatic Access to Cache Statistics for more information.
The following statistics may be useful in monitoring epoch:
14.4 Reclaim
The Reclaim Gem is responsible for reclaiming both dead and shadowed objects (see Shadow or Dead? for the difference between these types of garbage).
Shadowed objects are created naturally as your application modifies existing objects, so it is a good idea to always have the Reclaim Gem running to avoid shadowed objects accumulating. Some operations, such as migration, create a very large number of shadowed objects that need to be reclaimed.
After a mark/sweep operation — markForCollection or epoch — completes, there will be a number of dead objects that need to be reclaimed.
Although it is objects that are dead or shadowed, reclaim is done in pages. Pages that contain dead or shadowed objects may also contain some live objects; these live objects are copied to fresh pages, and the resulting page may then be reclaimed.
Reclaim is performed multi-threaded. Each thread within the Reclaim Gem is similar to a session, but runs within the Reclaim Gem process.
When the Reclaim Gem is running, its sessions examine pages marked reclaimable because they contain either dead or shadow objects, and reclaim fragments of space left by transactions that did not fill an entire page. This occurs in the background, with no specific action required.
Although it is recommended to allow the background processes to perform the reclaim, you can explicitly invoke it by executing:
Reclaimed space does not appear as free space in the repository until other sessions have committed or aborted all transactions concurrent with the reclaim transaction, and the Stone has disposed the commit record. If other users are logged in and holding up this process, you can determine which sessions are viewing the oldest commit record, thereby impeding reclaim. See the discussion under Further Tuning Garbage Collection.
Tuning Reclaim
Reclaim Configuration Parameters
The following configuration parameters are available to control the reclaim task, and are stored in GcUser’s UserGlobals.For details on modifying values, see here.
Reclaim Commit Frequency
A Reclaim Gem session will commit reclaim changes as soon as any one of the following conditions is met:
Controlling the impact of reclaim
Reclaim, particularly with a larger number of sessions configured for the Reclaim Gem, can perform quickly but place a large load on your system. If you are likely to be doing reclaim during periods where users will also need to use the system, you may wish to slow down reclaim. This can be done in a number of ways:
- Reduce the number of reclaim sessions using System class >> changeNumberOfReclaimGemSessions: with a argument of 1 or 0.
- Set #sleepTimeBetweenReclaimMs to ensure that reclaim Gem sessions pause between reclaim operations.
- Set #sleepTimeWithCrBacklogMs so that in case your system encounters a commit record backlog, the impact of reclaim is automatically reduced.
Speeding up reclaim
You can also setup your system to run reclaim with the maximum impact during off-hours. If you have a large amount of reclaim to perform, this allows the reclaim to finish more quickly. You can increase the number of Reclaim session to the maximum using:
System class >> startMaxReclaimGemSessions
This will start the number of sessions specified by STN_MAX_GC_RECLAIM_SESSIONS.
Avoiding disk space issues
Reclaim requires pages from the repository in order to copy non-dead objects. There are further steps that the stone must complete, before the space on the reclaimed pages is available again. So initially, reclaim will cause the amount of free space in the repository to drop.
Depending on overhead required by your system and the largest amount of reclaim that needs to be done at any time, you may want to configure a larger #reclaimMinFreeSpaceMb. This will ensure that reclaim pauses before your repository becomes dangerously low in free space.
Cache Statistics
Several cache statistics provide information about reclaim. These are visible by using statmonitor data viewed in VSD (the visual statistics display tool). You may also access methods in System to get the values programmatically; see Programmatic Access to Cache Statistics for more information.
The following Stone statistics may be useful in monitoring reclaim:
14.5 Running Admin and Reclaim Gems
Admin Gem Privileges required: GarbageCollection
The initial configuration for the Admin and Reclaim Gems are provided in the system configuration file for the stone; by default, $GEMSTONE/data/system.conf. These settings determine what is started automatically when the stone starts up. During runtime, you can start and stop the Admin Gem and change the number of Reclaim sessions that are running.
Configuring Admin Gem
The Admin Gem is enabled or disabled by the setting for the STN_ADMIN_GC_SESSION_ENABLED configuration option. By default, this is enabled, and normally you should leave this enabled. You can stop and restart the Admin Gem at runtime as needed.
Configuring Reclaim Gem
The number of Reclaim sessions is set by the STN_NUM_GC_RECLAIM_SESSIONS configuration option. By default, this is one, and you should normally keep at least one Reclaim session running. Most systems will benefit from increasing the number of Reclaim sessions. In general, we recommend running one Reclaim session for between 5 and 10 extents. You may need to experiment to find the correct balance for your system. The number of Reclaim sessions can be changed at runtime as needed.
To ensure that Reclaim sessions do not impact the number of user sessions, a separate configuration setting, STN_MAX_GC_RECLAIM_SESSIONS, configures the maximum number of Reclaim sessions you will be running.
By default, this is set to the number of extents on your system. This parameter cannot be changed without restarting the stone. The upper limit for the number for the number of Reclaim sessions that can be run under any configuration is 255.
While the number of Reclaim sessions should normally be less than or equal to STN_MAX_GC_RECLAIM_SESSIONS, it is possible to start a larger number of Reclaim sessions. However, this will reduce the number of user sessions that can login to this Stone. If your system does not have excess unused user sessions, you should be careful to configure STN_MAX_GC_RECLAIM_SESSIONS high enough that you will never want to run a larger number of Reclaim sessions.
Starting GcGems
You can ensure all configured GcGems are running using:
System startAllGcGems
If the Admin Gem is not running, start it. If the Reclaim Gem is not running, start it with the configured number of Reclaim sessions. Return true if the Admin Gem and at least one Reclaim sessions are started.
System startAdminGem
If the Admin Gem is not running, start it. Return true if the Admin Gem is running, false if the Admin Gem could not be started.
System startReclaimGem
If the Reclaim Gem is not running, start it with the configured number of Reclaim sessions. Return the number of Reclaim sessions that will be running. If the Reclaim Gem is already running, has not effect and returns the number of Reclaim sessions already running.
It may take a little time for the GcGems to complete login. The above methods do not block; they initiate the startup and return immediately. To wait a given period of time for the GcGems to start up:
System waitForAllGcGemsToStartForUpToSeconds: anInt
If the Admin Gem is not running, start it. If the Reclaim Gem is not running, start it with the configured number of Reclaim sessions. If all the GcGems have not started up within that time, return false. However, this does not necessarily mean that any GcGems have failed to start; on a slow system with a short timeout, this method may return false, even though all GcGems eventually start correctly.
To confirm that the GcGems are running,:
System hasMissingGcGems
Returns false if either the Admin Gem or the Reclaim Gem is not running.
To determine the number of Reclaim sessions that are currently running:
System reclaimGcSessionCount
Returns the total number of Reclaim sessions that are running.
Stopping GcGems
To ensure that the Admin Gem and all Reclaim sessions are stopped:
System stopAllGcGems
System stopAdminGemSystem stopReclaimGem
Adjusting the number of Reclaim sessions
You can adjust the number of Reclaim sessions that are running during the course of operation of your application. When there is a large amount of reclaim and little other load on your system, running a large number of Reclaim sessions will allow the reclaim work to complete more quickly. During normal operation, reducing the number of Reclaim sessions avoids using too many system resources and impacting users.
To set the number of Reclaim sessions that are running:
System changeNumberOfReclaimGemSessions: targetReclaimSessionCount
Start the ReclaimGem, if it is not running, with targetReclaimSessionCount Reclaim sessions.
targetReclaimSessionCount should be a number less than or equal to the value for STN_MAX_GC_RECLAIM_SESSIONS. Using a larger argument does not error, but may have consequences for user logins; see the discussion here.
Return the new target number of Reclaim sessions; Reclaim sessions will be started or stopped to reach this number. This method does not block, so it may take a little time before the correct number of Reclaim sessions is actually running.
Using this method only changes the currently running number of Reclaim sessions, but does not affect the configured number. After stopping the ReclaimGem, on restart the regular configured number of sessions will be started.
To change the default number of Reclaim sessions that will be started by default when the ReclaimGem starts up:
System configurationAt: #StnNumGcReclaimSessions
put: targetReclaimSessionCount.
This does not effect the number of Reclaim sessions that are currently running, if any. Changes to the runtime parameter do not persist if the Stone is restarted. For a permanent change, you should edit the configuration parameters in the configuration file used by the stone: STN_NUM_GC_RECLAIM_SESSIONS, and if necessary, STN_MAX_GC_RECLAIM_SESSIONS.
14.6 Further Tuning Garbage Collection
Multi-Threaded Scan
For large systems, it can take a considerable amount of time to scan the entire repository, as is required by a mark/sweep operation (or other operations such as listInstances). To allow these scans to complete faster, operations that scan the entire repository use multiple threads running in parallel. There is a trade-off between how fast the operation completes and how much of the system resources it uses. Obviously, the faster the scan completes, the less of anything else can be done on that system during that period.
The trade-off can be configured per operation and can be changed as the operation proceeds. You can choose to run it to complete as quickly as possible but use all the system resources, or with minimal impact on the rest of your application, but taking much longer to complete. You can switch between these approaches as often as you need to.
Tuning Multi-Threaded Scan
Each session has two variables that control the impact of the multi-threaded operation it is running:
|
The total CPU load level at which the scan starts to deactivate threads. |
These variables are arguments to all scan operations, although most scan operations have variants that use default values.
While these variables are passed in during operation startup, you can also update them while the scan is running. This enables you, for example, to reduce impact during working hours, while allowing more resources to be used during off hours.
Since the scan is running, of course, you need to update these variables from a second session, using the sessionId of the session that is running the scan.
One way to determine the session Id of the session that is running a scan operation is by checking the session holding the GcLock. However, while only one session can be holding the GcLock at a time, and markForCollection requires the GcLock, other operations such as GsObjectInventory, also may have the GcLock.
To access the upper limit on the number of threads:
System mtThreadsLimit: aSessionId
To update the upper limit on the number of threads:
System mtThreadsLimit: aSessionId setValue: anInt
System mtPercentCpuActiveLimit: aSessionId
System mtPercentCpuActiveLimit: aSessionId setValue: anInt
Both of these variables are used in tuning, but they have somewhat different uses. The primary way you will tune the impact on your system is by setting MtPercentCpuActiveLimit. The operations then controls its impact by activating or deactivating threads, up to a limit of MtThreadsLimit. The operation will proceed, using more or less resources at any particular time depending on what else is executing on your system. Note that the CPU load includes non-GemStone process running on this same machine, so if a machine is heavily used by non-GemStone processes, the operation may make little progress even if the GemStone repository itself is idle.
MtThreadsLimit acts as a ceiling on the impact as well. Since this limit is of more relevance within GemStone, on heavily loaded machines you may want to pay more attention to this limit to control the impact within the repository. This limit is also useful when you want to pause the scan. Setting the MtThreadsLimit to 0 means that the scan cannot perform work, but does not stop executing, it waits until a non-zero limit is set.
Cache Statistics
The following cache statistics are important for tuning multi-threaded scans. These are visible by using statmonitor data viewed in VSD (the visual statistics display tool); see VSD User’s Guide. You may also access methods in System to get the values programmatically; see Programmatic Access to Cache Statistics for more information.
|
The upper limit on the number of threads that can be running at any one time. |
|
|
The upper limit on percent of CPU that can be active before threads are deactivated. |
|
Memory Impact
Multi-threaded operations may require considerable heap memory. This memory requirement is not part of temporary object cache memory. You can configure your GEM_TEMPOBJ_CACHE_SIZE according to other application Gem requirements, or even configure the sessions performing repository scan operations with a very small temporary object cache size.
The amount of memory space that is needed depends primarily upon the current oopHighWater value, the number of threads, and the page buffer size. markForCollection uses a pageBufferSize of 128, epoch and writeSetUnionSweep use a size of 64, and it is an explicit argument to FDC.
The overhead associated with the oopHighWater value can be computed as:
(stnOopHighWater + 10M) / 2
The memory cost per thread is:
50K + (180K * pageBufSize)
For example, a system with an oopHighWater mark of 500M running eight threads with a page buffer size of 128 would require a minimum of about 440 MB of free memory.
Identifying Sessions Holding Up Voting
Voting is the 4th phase of garbage collection, described in Step 4. During this phase, each logged-in gem must vote on possibly dead objects. Sessions perform this vote on the next abort or commit that they execute, or on logout. If there are idle sessions that do not commit or abort, voting will not be able to complete.
You may find these sessions using:
System class >> notVotedSessionNames
The method System class >> descriptionOfSession: can help in tracking down such sessions. The array returned by this method includes the not voted status, as element 20. For details, see the comment in the image.
Tuning Write Set Union Sweep
The write set union sweep is the 5th phase of garbage collection, described in Step 5. It is performed by the Admin Gem.
The write set union sweep is performed using the Multi-Threaded Scan, and can be tuned using the following GcGem parameters:
Identifying Sessions Holding Up Page Reclaim
Reclaiming pages can proceed only up to those pages currently providing some session’s transaction view of the repository—that is, only up to the oldest commit record. When other sessions are logged in, reclaim stops at that point until all sessions using that commit record either commit or abort their transaction.
It can be helpful to identify which sessions are holding on to the oldest commit record. The method System class>>sessionsReferencingOldestCr returns an array of session IDs, which can be mapped to GemStone logins through System class>>currentSessionNames or System class>>descriptionOfSession:aSessionId. For example:
topaz 1> printit
System sessionsReferencingOldestCr
%
an Array
#1 5
topaz 1> printit
System currentSessionNames
%
session number: 2 UserId: GcUser
session number: 3 UserId: GcUser
session number: 4 UserId: SymbolUser
session number: 5 UserId: DataCurator
The method descriptionOfSession: is particularly useful in that it returns an array of descriptive information. The second element is the operating system process ID (pid), and the third element is the name of the node on which the process is running. For details, see the comment in the image.
Finding large objects that are using excessive space
If you know that you have large objects that are no longer needed, another way to free space is to explicitly remove references to them. To remove such objects, you must first identify them. Then you can find all references to them and remove those references.
Identify Larger Objects in the Repository
The following methods returns all objects that are over a specified size:
Repository >> allObjectsLargerThan: aSize
Repository >> fastAllObjectsLargerThan: aSize
These methods return a GsBitmap of all objects in the repository larger than aSize; objects for which you do not have read authorization are not included.
You can convert the GsBitmap to an Array using asArray, or retrieve only a specified number of results using removeCount: (which removes elements from the bitmap) or peekCount: (which does not remove them).
This method performs the repository wide search using the Multi-Threaded Scan. allObjectsLargerThan: uses two threads and a CPU limit of 100%, so it may have some impact, particularly on smaller host systems, and may take some time to complete. To complete the operation as quickly as possible, using as much of the system resources as necessary, you can use the fast version..
Finding named objects that are large
Named objects are Global variables; objects that have a reference by a Symbol name in some user’s SymbolDictionary. While there are some legitimate uses of Globals for environment-wide information, generally using global variables (other than for classes) is not good software engineering practice.
A common pattern is to use a global to keep some objects persistent, such as an expression:
UserGlobals at: #tempCollection put: IdentityBag new
If this collection and its contents is not deleted, it may continue to use space and may not be easily noticed. Using SessionTemps is preferred to avoid this problem.
The following expression causes GemStone to look through the symbol list for each user in AllUsers and gather information on any named objects larger than the SmallInteger aSize. Since it is looking for named references, it does not need to do a repository scan.
topaz 1> printit
AllUsers findObjectsLargerThan: aSize limit: aSmallInt
%
This method locates large collections or strings referenced by name; it will not locate collections stored within the class variables of classes, or in instances of classes. It returns an Array of up to aSmallInt elements, each of the form { { aUserId . aKey . anObject } }, where anObject is an object larger than aSize defined in the symbol list of aUserId, and aKey is the Symbol associated with that object.
Finding References to an Object that prevent garbage collection
Full reference path
To find a complete reference path to a particular object, you can use methods on the GsSingleRefPathFinder. This allows you to determine the complete reference path from a root object to the argument.
NOTE
This method runs in transaction, and may take a considerable time to run. Avoid using it in production systems.
To perform the scan, you create an instance of the GsSingleRefPathFinder for the object or objects, run the scan, and collect/view the results.
Steps to find a reference path:
Step 1. Create an instance with default settings:
inst := GsSingleRefPathFinder newForSearchObjects:
(Array with: mySearchObject).
inst runScan.
resultObjs := inst buildResultObjects.
buildResultObjects returns a collection of instance of GsSingleRefPathResult, which is a subclass of Array. Each element in the GsSingleRefPathResult represents an element in the reference path; it also has instance variables for the searchOop and status.
Step 4. 4) For display, collect the results as strings:
resultObjs collect: [:e | e resultString].
Steps 2-4 can be done using the GsSingleRefPathFinder method scanAndReport. For example:
(GsSingleRefPathFinder newForSearchObjects: { mySearchObject })
scanAndReport
These methods locate the first path from a root object to the argument object that is found, but there may be multiple paths.
Note that you cannot find references to a Class or Metaclass using these methods.
Once you have found the references to the unwanted object, set those references to nil. This allows the object to be removed during normal garbage collection.
Example 14.1 Finding reference path
| inst |
inst := GsSingleRefPathFinder newForSearchObjects:
{ PlusInfinity }.
inst runScan.
(inst buildResultObjects)
collect: [:e | e resultString]
%
anArray( 'Reference path for search oop 21393665 (Float)
1 207361 (SymbolDictionary)
2 1126401 (IdentityCollisionBucket)
3 1790721 (SymbolAssociation)
4 21393665 (Float)
')
In this example, PlusInfinity is a Float (#4). It is referred to in a SymbolDictionary (#1), using internal implementation objects (an IdentityCollisionBucket and a SymbolAssociation) that actually have the references.
GsSingleRefPathFinder provides a number of instance variables to parameterize the search:
- maxThreads
- lockWaitTime
- pageBufferSize
- percentCpuLimit
- maxLimitSetDescendantObjs
- maxLimitSetDescendantLevels
- printToLog
Defaults are provided, or you may send messages, for example to perform a less aggressive scan.
All References
You can search the repository for multiple references to an object by sending the following message:
topaz 1> printit
anObject findReferencesWithLimit: aSmallInt
%
This returns an Array of objects in the repository that reference anObject. The results will not include duplicates, if an object contains multiple references to anObject. The Array is limited to a maximum of aSmallInt elements, or use a negative to get unlimited results.
The resulting Array contains only references associated with GsObjectSecurityPolicies for which you have read authorization. If any references to anObject are protected by GsObjectSecurityPolicies for which you do not have read authorization, the last element of the result is the String 'Read Authorization Error encountered'.
findReferencesWithLimit: uses the Multi-Threaded Scan. It uses a default of two threads and up to 90% of the CPU.