3. Sharing Objects
This chapter describes how GemBuilder shares objects with the GemStone/S object repository.
3.1 Which Objects to Share?
Working with your client Smalltalk, you had one execution engine—the virtual machine—acting on one object space—your image. With GemBuilder, you have two execution engines and two object spaces, one of which is a full-fledged object repository for multiuser concurrent access, with transaction control, security protections, backups and logging.
You have two basic decisions in making use of the additional abilities provided by the GemStone server:
- Which object state should reside on the client, which on the server, and which in both object spaces?
- Which behavior should reside on the client, which on the server, and which in both object spaces?
Ultimately, the answer is dictated by the unique logic of your specific problem and solution, but these common patterns emerge:
Client presents user interface only; state (domain objects) and application logic reside on server; server executes all but user interface code. A web-based application that uses the client merely to manage the browser needs little functionality on the client, and what it does need is cleanly delimited.
State resides on both client and server; client manages most execution; server is used mainly as a database. A Department of Motor Vehicles could use a repository of driver and vehicle information, properly defined, for a bevy of fairly straightforward client applications to manage driver’s licenses, parking permits, commercial licenses, hauling permits, taxation, and fines.
Execution occurs, and therefore state resides, on both client and server. At specified intervals, clients of a nationwide ticket-booking network download the current state of specific theaters on specific dates. Clients book seats and update their local copies of theaters until they next connect to the repository. To resolve conflicts, server and client engage in a complex negotiation.
For these and other solutions, GemBuilder provides several kinds of client- and server-side objects, and a mechanism—a connector—for describing the association between pairs of root objects across the two object spaces.
Three kinds of objects help a GemBuilder client and a GemStone server repository share state and execution: forwarders, stubs, and replicates.
Forwarder—is a proxy: a simple object that knows only which object in the other space it is associated with. It responds to a message by passing it to its associated master object in the other object space, where state is stored and execution occurs remotely. Forwarders can be on the client, for server master objects, or on the server for client master objects.
Replicate—is an object associated with a particular object in the other object space. The replicate copies some or all of the other object’s state, which it synchronizes at appropriate times. It implements all messages it expects to receive. By default, the replicate executes locally. However, you can use performOnGsServer: to forward a message to the server.
Stub—is a proxy that responds to a message by becoming a replicate of its counterpart object, then executing the message locally. Stubbing is a way to minimize memory use and network traffic by bringing only what is needed when it is needed.
Connector—associates a root client object with a root server object, typically resolving objects by name, although there are other ways. When connected, they synchronize data or pass messages in either direction or take no action at all, as specified. For more information on connectors, see Chapter 4.
Whatever combination of these elements your application requires, subsystems of objects will probably reside on both the client and the server. Some subset of these subsystems will need state or behavior on both sides: some objects will be shared.
3.2 Class Mapping
Before GemBuilder can replicate an object, it must know the respective structures of client and repository object and the mapping between them. Although not strictly necessary for forwarders, this knowledge improves forwarding performance, saving GemBuilder an extra network round-trip during the initial connection.
GemBuilder uses class definitions to determine object structure. To replicate an object:
- both client and server must define the class, and
- the two classes must be mapped by name or by using a class connector.
GemBuilder uses this mapping for all replication, whether at login or later.
Unlike connectors for replicates or forwarders, class connectors by default do not update at connect time. If class definitions differ on the client and the server, it is usually for a good reason; you probably don’t want to update GemStone with the client Smalltalk class definition, or vice-versa.
GemBuilder predefines special connectors, called fast connectors, for the GemStone kernel classes. For more information about fast connectors, see Connecting by Identity: Fast Connectors.
If there is no connector for a class, and a mapping for that class is required, GemBuilder will attempt to map the client and server classes with the same name. By default, it will also create a connector for those classes. If the configuration parameter generateClassConnectors is false, GemBuilder will still map the classes by name, but will not create a connector. The difference is that without a connector, the mapping only lasts until the session logs out, and any other sessions logged in will not have that mapping. If a connector is created, it is associated with the session parameters object, and any session logged in using that session parameters object will have that class mapping created at login time.
Automatic Class Generation and Mapping
You can configure GemBuilder to generate class definitions and connectors automatically. When so configured, if GemBuilder requires the GemStone server to replicate an instance of a client class that is not already defined on the server, then at the first access, GemBuilder generates a server class having the same schema and position in the hierarchy, and a class connector connecting it to the appropriate client class. Conversely, if the client must replicate an instance of a GemStone class that is not already defined in client Smalltalk, GemBuilder generates the client Smalltalk class and the appropriate class connector. If superclasses are also undefined, GemBuilder generates the complete superclass hierarchy, as necessary.
You can control automatic class generation with the configuration parameters generateServerClasses and generateClientClasses (described starting here). These settings are global to your image.
- If you have disabled automatic generation of GemStone classes by setting generateServerClasses to false (the default), situations that would otherwise generate a server class instead raise the exception GbsClassGenerationError.
- If you have disabled automatic generation of client Smalltalk classes by setting generateClientClasses to false (the default), situations that would otherwise generate a client Smalltalk class instead raise the exception GbsClassGenerationError.
- You can disable class connector generation by setting generateClassConnectors to false. When classes are generated or mapped by name, no connector is generated.
GemBuilder deposits automatically generated GemStone server classes in the GemStone symbol dictionary UserClasses, which it creates if necessary. Automatically generated client Smalltalk classes are deposited in the current package or parcel.
Automatic class generation is primarily useful as a development-time convenience. In an application runtime environment, we recommend having all necessary classes predefined in both object spaces, and having a connector defined for each class before logging in. This can improve performance by avoiding unnecessary work when the class is first accessed.
Schema Mapping
By default, when you map a client class to a GemStone server class, GemBuilder automatically maps all instance variables whose names match, regardless of the order in which they are stored. (You can change this default mapping to accommodate nonstandard situations.)
If you later change either of the mapped class definitions, GemBuilder automatically remaps identically named instance variables.
Behavior Mapping
When GemBuilder generates classes automatically, it only copies the definition of the class, not the methods of the class.
Replicated instances depend on methods implemented in the object space in which they execute. During development, it may be simplest to use GemBuilder’s programming tools to implement the same behavior in both spaces. For reliability and ease of maintenance, however, some decide to remove unnecessary duplication from production systems and to define behavior only where it executes.
Mapping and Class Versions
Unlike the client Smalltalk language, GemStone Smalltalk defines class versions: when you change a class definition, you make a new version of the class, which is added to an associated class history. (For details, see the chapter entitled “Class Versions and Instance Migration” in the GemStone Programming Guide.)
If you change a class definition on the client or server, and decide to update one class definition with the other, the result depends on the direction of the update:
- Updating a client Smalltalk class from a GemStone server class regenerates the client class and recompiles its methods.
- Updating a GemStone server class from a client Smalltalk class creates a new version of the class.
NOTE
A class connector connects to a specific GemStone class version, the version that was in effect when the connector was connected. Instances of a given class version are not affected by a connector connected to another class version.
Migration can affect this issue. See Chapter 8, “Schema Modification and Coordination”.
3.3 Forwarders
The simplest way to share objects is with forwarders, simple objects that know just one thing: to whom to forward a message. A forwarder is a proxy that responds to messages by forwarding them to its counterpart in the other object space.
Forwarders are particularly useful for large collections, generally resident on the GemStone server, whose size makes them expensive to replicate and cumbersome to handle in a client image.
- The most common kind of forwarder is a forwarder to the server: a client Smalltalk object, an instance of GbsFowarder, that knows only which GemStone server object it represents. It responds to all messages by passing them to the appropriate server object, where its associated state resides and behavior is implemented. (For historical reasons, this is the kind of forwarder usually meant when a discussion merely says “forwarder.” This kind of forwarder is also called a server forwarder.)
- A forwarder to the client is a GemStone server object that knows only which client Smalltalk object it represents. It responds to all messages by passing them to its associated client Smalltalk object, where state resides and behavior is implemented.
You can create forwarders in several ways:
- Create a connector with a postconnect action of #forwarder or #clientForwarder. For example, connect the server global variable BigDictionary as a forwarder to the server so that it isn’t replicated in the client.
- Specify that a given instance variable must always appear on the client as a forwarder to the server (using a replication specification, discussed starting here). For example, a client class might implement a specification that declares the instance variable inventory as a forwarder to the server.
- Prefix fw to a method name to return a forwarder from any message-send to the server. For example, to return a forwarder from a GemStone server name lookup, send the GbsSession fwat: or fwat:ifAbsent: instead of at: or at:ifAbsent:.
- Override all these by implementing a class method instancesAreForwarders on the client class to return true, and all instances of that class and its subclasses will be forwarders to the server. Subclasses of GbsServerClass already respond true to this message; GbsServerClass is an abstract class, and all instances that inherit from it become forwarders to the server. When sent to a class that inherits from GbsServerClass, the instance creation methods new and new: create a new instance of the class on the server and return a forwarder to that instance.
Sending Messages
On the client, when a forwarder to the server receives a message, it sends the message to its counterpart on the GemStone server—presumably an instance that can respond meaningfully. The target server object’s response is then returned to the forwarder on the client, which then returns the result.
When a forwarder to the client receives a message on the server, it forwards the message to the full-fledged client object to which it is connected. This object’s response is returned to the client forwarder, which returns the result represented as a server object.
Arguments
Before a message is forwarded to the GemStone server, arguments are translated to server objects. As a message is forwarded to the client, its arguments are translated to client Smalltalk objects.
When an argument is a block of executable code, special care is required: for details, see Replicating Client Smalltalk BlockClosures.
Results
The result of a message to a client forwarder is a GemStone Smalltalk object in the GemStone server.
The result of a message to a server forwarder is the client Smalltalk object connected to the server object returned by GemStone—usually a replicate, although a forwarder might be desirable under certain circumstances.
To ensure a forwarder result, prefix the message to the forwarder with the characters fw. For example:
Defunct Forwarders
A forwarder contains no state or behavior in one object space, relying on the existence of a valid instance in the other. When a session logs out of the server, communication between the two spaces is interrupted. Forwarders that relied on objects in that session can no longer function properly. If they receive a message, GemBuilder raises an error complaining of either an invalid session identifier or a defunct forwarder.
You cannot proceed from either of these errors; an operation that encounters one must restart (presumably after determining the cause and resolving the problem).
GemBuilder cannot safely assume that a given server object will retain the same object identifier (OOP) from one session to the next. Therefore, you can’t fix a defunct forwarder error simply by logging back in.
(If a connector has been defined for that object or for its root, then logging back in will indeed fix the error, because logging back in will connect the variables. But in that case, it’s the connector, not the forwarder, that repairs damaged communications.)
Consider the following forwarder for the global BigDictionary:
conn := GbsNameConnector
clientName: #BigDictionary
serverName: #BigDictionary.
conn beForwarderOnConnect.
GBSM addGlobalConnector: conn
When a GemBuilder session logs into the GemStone server, BigDictionary becomes a valid forwarder to the current server BigDictionary. But when no session is logged into the server, sending a message to BigDictionary results in a defunct forwarder error.
GemBuilder’s configuration parameter connectorNilling, when true, assigns each connector’s variables to nil on logout. This applies only to session-based name, class variable, or class instance variable connectors that have a postconnect action of #updateST or #forwarder (see Connectors). This usually prevents defunct stub and forwarder errors, replacing them with nil doesNotUnderstand errors.
3.4 Replicates
Sometimes it’s undesirable to dispatch a message to the other object space for execution—sometimes local execution is desirable, even necessary, for example, to reduce network traffic. When local state and behavior is required, share objects using replicates instead of forwarders. Replicates are particularly useful for small objects, objects having visual representations, and objects that are accessed often or in computationally intensive ways.
Like a forwarder, a replicate is a client Smalltalk object associated with a server object that the replicate represents. Unlike a forwarder, replicates also hold (some) state and implement (some) behavior. Replicates synchronize their state with that of their associated server object.
To do so, GemBuilder must know about the structure of the two objects and the mapping between those structures. GemBuilder manages this mapping on a class basis: each replicate must be an instance of a class whose definition is mapped to the definition of the corresponding class in the server object space. GemBuilder handles many obvious cases automatically, but nonstandard mappings require you to implement certain instance and class methods. Nonstandard mappings are discussed starting here.
Synchronizing State
After a relationship has been established between a client object and a GemStone server object, GemBuilder keeps their states synchronized by propagating changes as necessary.
When an object changes in the server, GemBuilder automatically updates the corresponding client Smalltalk replicate. By default, GemBuilder also detects changes to client Smalltalk replicates and automatically updates the corresponding server object.
The stages and terminology of this synchronization are as follows:
- When an object is modified in the client, leaving its server counterpart out of date, the client object is now referred to as dirty.
- When the state of dirty client objects is transferred to their corresponding server objects, this is called flushing.
- When a server object is modified in the server, leaving its client counterpart out of date, the server object is now dirty. This can occur during execution of server Smalltalk, or at a transaction boundary when changes committed by other sessions become visible to your session.
- When the state of dirty server objects is transferred to their corresponding client objects, this is called faulting.
Together, GemBuilder and the GemStone server manage the timing of faulting and flushing.
Faulting
GemBuilder faults objects automatically when required. Faulting is required when a stub receives a message, requesting it to turn itself into a replicate. (see stubbing here)
Faulting may also be required when:
- Connectors connect; this typically occurs at login, the beginning of a GemStone session, but you can connect and disconnect connectors explicitly during the course of a session using either code or the Connector Browser. Faulting may or may not occur upon connection, depending on the post-connect action specified for the connector.
- A server object that has been replicated to the client is modified on the server. This can happen in two cases:
1. GemStone Smalltalk execution in your session modifies the state of the object. GemStone Smalltalk execution occurs when a forwarder receives a message, or in response to any variant of GbsSession >> evaluate:.
2. Your session starts, commits, aborts, or continues a transaction—passes a transaction boundary—which refreshes your session's private view of the repository. If the server object has been changed by some other concurrent session, and that change was committed, the object's new state will be visible when your session refreshes its view.
In both of these cases, the replicate's state is now out of date, and cannot be used until updated by faulting. Depending on the replicate's faultPolicy (see here) the new state will either be faulted immediately, or the replicate becomes a stub, and will be faulted the next time it receives a message.
Flushing
GemBuilder flushes dirty client objects to the GemStone server at transaction boundaries, immediately before any GemStone Smalltalk execution, or before faulting a stub.
Flushing is not the same as committing. When GemBuilder flushes an object, the change becomes part of the session’s private view of the GemStone repository, but it doesn’t become part of the shared repository until your session commits—only then are your changes accessible to other users.
For GemBuilder to flush a changed object to the server, that object must be marked dirty, that is, GemBuilder must be made aware that the object has changed. Objects are, by default, marked dirty automatically. In addition, you can explicitly mark objects dirty.
Marking Modified Objects Dirty Automatically
By default, GemBuilder uses VisualWorks automatic mark dirty capability. This detects modifications to replicates on the client so that modified replicates can be automatically marked dirty. This mechanism is fast, reliable, and does not affect client objects that are not replicates. Thus, we recommend always using automatic dirty-marking. Automatic dirty-marking is enabled by default.
To disable automatic dirty-marking, execute:
GbsConfiguration current autoMarkDirty: false
or use the Settings Tool to turn off the configuration parameter autoMarkDirty. It is enabled or disabled globally for the client; you cannot enable automatic dirty-marking for only some classes or objects in the client virtual machine. If you disable automatic dirty-marking, your application must manually mark modified client replicates dirty as described in the next section.
Marking Modified Objects Dirty Manually
Generally, we recommend you use the automatic mechanisms. You can instead, if you wish, mark objects dirty explicitly in your code. The automatic mechanism is faster and much more reliable—if you miss even one place where a shared object is modified, your application will misbehave.
To manually mark a replicate dirty, send markDirty to the replicate immediately after each time your application modifies it. If a replicate is modified on the client but not marked dirty, the modification will be lost eventually. The object could be overwritten with its GemStone server state after the application has executed code on the server, or at the next transaction boundary. Even if the client object is never overwritten, the modification will never be sent to the server.
Minimizing Replication Cost
Replicating the full state of a large and complex object graph can demand too much memory or network bandwidth. Optimize your application by controlling the degree and timing of replication; GemBuilder provides three ways to help:
Instance Variable Mapping—Modify the default class map to specify how widely through each object to replicate—which instance variables to connect and which to prune as never being of interest in the other object space. You can also specify the details of an association between two classes whose structures do not match.
Stubbing—Specify how deeply through the network to replicate, how many layers of references to follow when faulting occurs.
Replication Specifications—Specify how widely or deeply through each object to replicate—of a class’s mapped instance variables, which to replicate and which to stub.
Instance Variable Mapping
As discussed in Class Mapping, before GemBuilder can replicate objects, it must know their respective structures and the mapping between them. By default GemBuilder maps instance variables by name. You can override this default either by suppressing the copying of certain instance variables, or by explicitly specifying a mapping between nonmatching names.
Suppressing Instance Variables
Some client Smalltalk objects must define instance variables that are relevant only in the client environment—for example, a reference to a window object. Such data is transient and doesn’t need to be visible to the GemStone server. Situations can also arise in which the server class defines instance variables that a given application will never need; many applications can share repository objects without necessarily sharing the same concerns. Mapping allows your application to prune parts of an object.
Suppress the replication of an individual instance variable simply by omitting its name from its counterpart’s class definition:
- If a client object contains a named instance variable that does not exist in its GemStone server counterpart, the value of that variable is not replicated in the server. When GemBuilder faults the server object into the client, the client’s suppressed instance variable remains unchanged.
- Likewise, if a server object contains a named instance variable that does not exist in its client counterpart, the value of that variable is not replicated in the client. When GemBuilder flushes the object into the server, the server object’s suppressed instance variable remains unchanged.
You can also suppress instance variable mappings by implementing the client class method instVarMap. For example:
TestObject class>>instVarMap
^super instVarMap ,
#( (nil serverName)
(clientName nil) )
The first component of the return value, a call to super instVarMap, ensures that all instance variable mappings established in superclasses remain in effect.
Appended to the inherited instance variable map, an array contains the pairs of instance variable names to map. The first pair (nil serverName) specifies that the server instance variable serverName will never be replicated in the client. The second pair (clientName nil) specifies that the client instance variable clientName will never be replicated in the server.
Nonmatching Names
You can also specify an explicit instance variable mapping between the server and the client:
- to map two instance variables whose names don’t match, or
- to prevent the mapping of two instance variables whose names do match.
In this way your application can accommodate differing schemas.
To specify mappings from one instance variable name to another, specify each name in the mapping array. For example:
TestObject class>>instVarMap
^super instVarMap ,
#( (clientName serverName) )
Appended to the inherited instance variable map, a single pair declares that the instance variable clientName in the client maps to the instance variable serverName in GemStone.
One implementation can both prune irrelevancy and accommodate differing schemas. for example,
Book class>>instVarMap
^super instVarMap ,
#( (title title)
(author author)
(nil pages)
(publisher nil)
(copyright publicationDate) )
The first two pairs of instance variables change nothing: they explicitly state what would happen without this method, but are included for completeness.
(nil pages) specifies that the client application does not need to know a books page count and therefore this server-side instance variable is not replicated in the client.
(publisher nil) specifies that the client application needs (and presumably assigns) the instance variable publisher, which is never replicated in the server.
(copyright publicationDate) maps the client class Book’s instance variable copyright to the server class Book’s instance variable publicationDate.
Stubbing
Often an application has need of certain instance variables, but not all at once. For example, it’s impractical to replicate the entire hierarchy of BigDictionary at login: users will experience unacceptable network delays, and the client Smalltalk image can’t handle data sets as large as the GemStone server can. Furthermore, it’s unnecessary: only a small number of objects will be needed for the current task. To help prevent this kind of over-replication, GemBuilder provides stubs.
A stub, like a forwarder, is also a proxy associated with a server object. Unlike a forwarder, however, when a stub receives a message, it does not send the message across to the other object space. Instead, it faults its server counterpart into the client image. The client Smalltalk replicate then responds to the message.
When GemBuilder faults automatically, it replicates the object hierarchy to a certain level, then creates stubs for objects on the next level deeper than that. The number of levels that are replicated each time is the fault level.
The fault level of 1 follows an object’s immediate references and faults those in; the fault level of 2 follows one more layer of references and replicates those objects, too.
Figure 3.1 illustrates an application with where object a has a fault level of 1.
Faulting at Login
At login, the connectors connect, and objects a, b, and c are replicated; objects d and e are stubbed; objects f and g are ignored.
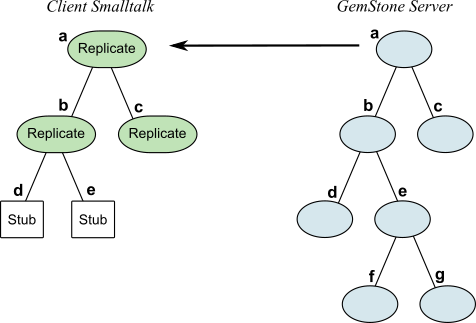
Faulting in Response to a Message
When object e, which is a stub, receives a message, it faults in a replicate of its counterpart GemStone server object.
A stub faults in a replicate in response to a message. Therefore, direct references to instance variables can cause problems. Direct access is not a message-send; the stub will not fault in its replicate, because it receives no message; neither can it supply the requested value. To avoid this problem, use accessor methods to get or set instance variables.
The following sequence demonstrates the problem. The object starts as a replicate in client Smalltalk:
demonstrateProblem
| firstTemp secondTemp |
firstTemp := size. "Size is an inst var of the receiver.
FirstTemp now has a valid value."
self stubYourself. "self is now a stub, and has no
instance variable values"
secondTemp := size. "Since this access is not a message
send, it does not unstub self.
SecondTemp now contains an invalid
value, most likely nil."
^Array with: firstTemp with: secondTemp.
Using an accessor method, on the other hand, causes the stub to be faulted in and yields the correct result:
self size. "This is a message, and faults the stub."
e is now a replicate, as shown in Figure 3.2. The new replicate responds to the message.
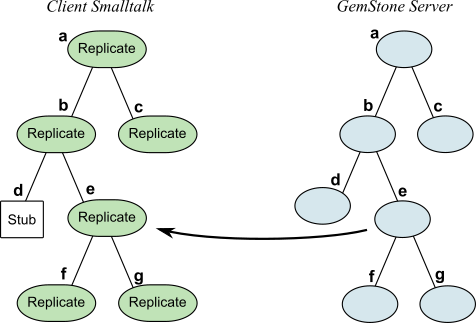
Faulting in Changes From Other Sessions
Now, suppose another session commits a change to b?
Each session maintains its own view of the GemStone object server’s shared object repository. The session’s private view can be changed by the client application when it adds, removes, or modifies objects—that is, you can see your own changes to the repository—or the Gem can change your view at transaction boundaries or after a session has executed GemStone Smalltalk.
A Gem maintains a list of repository objects that have changed and notifies GemBuilder of any changes to objects it has replicated. If it finds any changed counterparts, it updates the client object with the new GemStone value.
The way in which these changes depends on the server product, and with 32-Bit GemStone/S, on a GemBuilder configuration setting.
GemStone/S 64 Bit
Because network overhead is minimal, all objects are immediate-faulted. When GemBuilder detects a change in a repository object, it updates the replicate immediately.
GemStone/S (32 bit)
Replicates and stubs respond to the message faultPolicy. The default implementation returns the value of GemBuilder’s configuration parameter defaultFaultPolicy: either #lazy or #immediate.
- A lazy fault policy means that, when GemBuilder detects a change in a repository object, it turns the client counterpart from a replicate into a stub. The object will remain a stub until it next receives a message.
- An immediate fault policy means that, when GemBuilder detects a change in a repository object, it updates the replicate immediately.
If another session commits a change to b, and b’s fault policy is lazy, b becomes a stub. If b’s fault policy is immediate, b is updated.
The default fault policy is lazy, to minimize network traffic. For more information, see the description of defaultFaultPolicy in the Settings Browser. For examples, browse implementors of faultPolicy in the GemBuilder image.
Overriding Defaults
Because linked sessions may be able to access the gem with lower latency, GemBuilder ships with faultLevelLnk set to 2 and faultLevelRpc set to 4. In this way, linked sessions replicate less at login, faulting in objects as they are needed.
- You can override these defaults for specific instance variables of specific replicates.
- You can also stub or replicate certain objects explicitly.
To specify fault levels for all instance variables, implement a class method replicationSpec for the client class. Replication specifications are versatile mechanisms described starting here.
To cause a replicate to become a stub, send it the message stubYourself. This can be useful for controlling the amount of memory required by the client Smalltalk image. Explicit control of stubs is discussed in Optimizing Space Management.
Sometimes stubbing is not desirable, either for performance reasons or for correctness. For example, primitives cannot accept stubs as arguments if the primitive accesses the instance variables of the argument. If your application uses an object as an argument to a primitive, you must either prevent that object from ever becoming a stub, or ensure that it is replicated before the primitive is executed.
To cause a stub to become a replicate, send it the message fault. Stubs respond to this message by replicating; replicates return self. The message faultToLevel: allows you to fault in several levels at once, as specified.
Defunct Stubs
Faulting in a stub relies on the existence of a valid GemStone server object to replicate or forward to. If an object is stubbed and the session logs out, a message to that stub raises an error complaining that it is defunct. For example, suppose MyGlobal is modified in a 32-bit server, thereby stubbing it in your client session. If the session logs out before MyGlobal is faulted back in, the client Smalltalk dictionary contains a defunct stub.
Because GemBuilder cannot safely assume that a given object will retain the same object identifier from one session to the next, it cannot simply fix the problem at next login. That’s the job of a connector: to reestablish at login the stub’s relationship to GemStone. A connector can do so either directly, by connecting the stub itself, or transitively, by connecting some object that refers to the stub.
If you’ve defined a connector for MyGlobal, logging back into GemStone reconnects it.
Now, suppose an instance variable of MyGlobal becomes a stub shortly before a session logs out. Sending a message to this variable will produce a defunct stub error. At next login, MyGlobal’s connector will fault in the variable. You can then retry the message, but only by means of a message sent to MyGlobal (or another connected object). If the application is maintaining a direct reference to the previous defunct stub, the error will persist.
NOTE
You cannot proceed from a defunct stub error. After you’ve encountered this error, determined the cause, and corrected the problem, you must restart the client Smalltalk operation that encountered the defunct stub.
Replication Specifications
By default, when GemBuilder replicates an instance of a connected class, it replicates all that class’s instance variables to the session’s specified fault level. You can further refine faulting by class, however, with specific instructions for individual instance variables.
Each class replicates according to a replication specification (hereafter referred to as a replication spec). The replication spec allows you to fault in specified instance variables as forwarders, stubs, or replicates that will in turn replicate their instance variables to a specified level.
By default, a class inherits its replication spec from its superclass. If you haven’t changed any of the replication specs in an inheritance chain, then the inherited behavior is to replicate all instance variables as specified by the configuration parameters faultLevelLnk and faultLevelRpc.
To modify a class’s replication behavior in precise ways, implement the class method replicationSpec. For example, suppose you want class Employee’s address instance variable always to fault in as a forwarder:
Employee >> replicationSpec
^ super replicationSpec ,
#( ( address forwarder )).
To ensure that replication specs established in superclasses remain in effect, Example appends its implementation to the result of:
super replicationSpec
Appended to the inherited replication spec are nested arrays, each of which pairs an instance variable with an expression specifying its treatment at faulting:
(instVar whenFaulted)
- the client-side name of an instance variable, or
- the reserved identifier indexable_part, specifying an object’s unnamed indexable instance variables, such as the elements of a collection.
stub—faults in the instance variable as a stub.
forwarder—faults in the instance variable as a forwarder to the server.
min n—faults in the instance variable and its referents as replicates to a minimum of n levels. min 0 = replicate.
max m—faults in the instance variable and its referents as replicates to a maximum of m levels. max 0 = stub.
replicate—faults in the instance variable as a replicate whose behavior will be subject to the configuration parameters faultlevelRpc and faultLevelLnk, relative to the root object being faulted.
By default, an instance variable’s behavior is replicate. Your application needn’t specify replicate unless to restore behavior overridden in a superclass.
TestObject class>>replicationSpec
^super replicationSpec ,
#( (instVar1 stub)
(instVar2 forwarder)
(instVar3 max 0)
(instVar4 min 0)
(instVar5 max 2)
(instVar6 min 2)
(instVar7 replicate)
(indexble_part min 1) )
Replication Specifications and Class Versions
As explained in Mapping and Class Versions, client Smalltalk classes connect not simply to GemStone Smalltalk classes, but to specific server class versions. A class connector connects to only one server class version.
A replication spec, therefore, affects only client instances connected to instances of the correct GemStone class version.
Suppose, for example, that you define and redefine class X in the server until its class history lists three versions. Your client Smalltalk class is connected to Version 2. Class X’s replication spec will affect server instances of Class X, Version 2. If the server contains instances of Class X, Versions 1 or 3, the replication spec will not affect them.
Multiple Replication Specifications
It’s not always possible to define one replication spec that works well for all operations in an application. Some queries or windows may require a different object profile than others in the same application and session; a replication spec crafted to optimize one set of operations can make others inefficient.
By default, the message replicationSpec returns the default replication spec. Change this by sending the message replicationSpecSet: #someRepSpecSelector to an instance of GbsSession. The selector of the replicationSpec acts as the named of the replication spec. Using this message to specify the replicationSpec to use to perform a particular operation, you can specify multiple replication specs, selecting one dynamically according to circumstances. The following procedure shows how:
Step 1. Decide on a new name, such as replicationSpec2.
Step 2. Implement Object class >> replicationSpec2 to return self replicationSpec.
Step 3. Reimplement replicationSpec2 as appropriate in those application classes that need it.
Step 4. Immediately before your application performs the query or screen fetch or other operation that requires the second replication spec, send replicationSpecSet: #replicationSpec2 to the current GbsSession instance, specifying the selector symbol of the new replicationSpec method.
Step 5. Immediately after the operation completes, send replicationSpecSet: #replicationSpec to the GbsSession to restore replication. If the session could be addressed from more than one client Smalltalk process, your application should use a semaphore to control access to the session.
For example, suppose your application has a class Employee, with instance variables firstName, lastName, and address. address contains an instance of class Address. The application has one screen that displays the names from a list of employees, and another screen that displays the zip codes from a list of employee addresses. Here’s how to replicate only what’s needed:
Step 1. Define a new replication spec with the selector empNamesRepSpec.
Step 2. Implement Object class >> empNamesRepSpec as:
^self replicationSpec.
Step 3. Implement Employee class >> empNamesRepSpec as:
^#((firstName min 1) (lastName min 1) (address stub))
Step 4. Define another replication spec with the selector empZipcodeRepSpec.
Step 5. Implement Object class >> empZipcodeRepSpec as:
^self replicationSpec
Step 6. Define Employee class >> empZipcodeRepSpec as:
^#((firstName stub) (lastName stub) (address min 2))
and Address class >> empZipcodeRepSpec as:
^#((city stub) (state stub) (zip min 1))
Step 7. Before opening the employee names screen, send:
myGbsSession replicationSpecSet: #empNamesRepSpec
Restore it to #replicationSpec after opening the window.
Step 8. Before opening the zip code window, send:
myGbsSession replicationSpecSet: #empZipcodeRepSpec
Restore it to #replicationSpec after opening the window.
For each window, the procedure above reduces the number of objects retrieved to the minimum required. Other objects fault in as stubs; if subsequent input requires them, they are retrieved transparently.
Managing Interobject Dependencies
Replication specs are ordinarily an optimization mechanism. Some applications, however, require a replication spec to function correctly. If the structural initialization of an object depends on other objects, you must implement replication specs to ensure that, when GemBuilder replicates an object, it also replicates those objects it depends on.
Hashed collection classes that wish to replicate instances between client and server should answer true to the message #gbsMustDeferElements. This is the recommended approach.
When an object whose class answers true to #gbsMustDeferElements is faulted to the client, the elements are not added to the collection until the replication of those elements is complete. This ensures that all of the information necessary to compute the hash of the element is present before adding it to the collection; if added earlier, its hash might change as its replication continued, corrupting the collection.
There is one exception to this requirement. Hashed collections that compute hash purely on the identity hash of their elements may answer false to #gbsMustDeferElements, since their hash values are computed strictly on the identity of the elements themselves, which is always present.
NOTE
If you do not use #gbsMustDeferElements (the recommended approach), you must independently address the issues described in the following paragraphs.
For example, in order to create a Dictionary when replicating it from the server, we need to be able to send hash to each key to determine its location in the hash table (hash values aren’t necessarily the same in the server as they are in the client). So, if GemStone replicates a Dictionary, it must also at a minimum replicate the association and the key in the association, so it can compute the hash. The default implementation for Dictionary class >> replicationSpec therefore contains #(indexable_part min 1), and Association class >> replicationSpec contains #(key min 1).
This works for Dictionaries with simple keys such as strings, symbols or integers. If an application has dictionaries with complex keys, though, additional replication specs can be required. For example, if you are storing Employees as keys in a dictionary, and you’ve implemented = and hash in Employee to consider the firstName and lastName, then you must ensure that when a dictionary containing Employees is traversed, so are the associations, the employees, and the firstName and lastName.
You could ensure this by implementing Employee class >> replicationSpec to include #(firstName min 1) and #(lastName min 1). Or, if you had a special Dictionary class for Employees, you could include #(indexable_part min 3) in that dictionary class’s replication spec. However, this could cause the entire Employee to be replicated whenever one of these dictionaries is replicated, rather than just the firstName and lastName.
We recommend that you use the default replication spec #replicationSpec as the base replication spec for all classes to reflect interobject dependencies. When defining other replication specs, make sure the default implementation in Object is:
^self replicationSpec
Ensure that subclass implementations of the new replicationSpec method do not stray from the default, so as not to break interobject dependencies.
Precedence of Multiple Replication Specs
It’s possible to implement replication specs that appear to contradict each other. Such apparent conflicts are resolved deterministically according to the order in which instance variables appear in a replication spec and the order in which objects are replicated. If a superclass specifies one way of handling an instance variable, and a subclass reimplements replicationSpec to handle the same variable in a different way, the last occurrence takes precedence.
For example, suppose the value returned from sending replicationSpec to the subclass is:
#((name min 1) (name max 2))
The last occurrence of the instance variable is max 2, and therefore takes precedence.
If subclass implementations of replicationSpec always append their results to super replicationSpec, the subclass will reliably override the superclass handling of a given instance variable. The recommended approach is:
^super replicationSpec, #((name max 2))
^#((name max 2)), super replicationSpec.
Another apparent contradiction can arise between parent and child objects. For example, suppose Employee refers to an Address, which refers to a complex object County. The Employee replicationSpec includes #(address min 5), specifying that several levels of the County object are to be replicated. But if Address includes #(county max 1), it modifies Employee’s handling of address.
Employee specifies, “Get at least 5 levels of address.” Address specifies, “Whatever you do, don’t get more than one level of county.” The apparent contradiction is resolved by the order in which these specifications are encountered: because Address is encountered after Employee, Address takes precedence.
If your object network includes cycles, different replication specs could take effect at different times, depending on which object is the replication root at any given time. Given a specific root object, however, it’s always possible to determine the exact effect of a set of replication specs.
Forwarding Messages to Server Objects
Through Replicates and Stubs
Most messages received by a client replicate execute their behavior locally on the client. However, it is possible to make a replicate or a stub forward a message to its server counterpart, somewhat like a forwarder does. This is done with the following message:
performOnGsServer: selector withArguments: argumentArray
For messages with no arguments, you may use
performOnGsServer: selector
The server object will be sent a message with the given selector and arguments, and the result will be replicated to the client. This gives you a great deal of flexibility as to which behaviors are executed on the server and which on the client.
Customized Flushing and Faulting
You can customize both flushing and faulting to change object structure arbitrarily, if your application requires it. You can even create a class in the server GemStone that maps to a client Smalltalk class with a different format—for example, a format of bytes on the client but pointers in the server.
Modifying Instance Variables During Faulting
You can customize object retrieval by using buffers for the client counterparts of GemStone server objects as they are faulted in. You can then process the contents of these buffers in any manner required.
To provide these buffers, reimplement the class methods:
namedValuesBuffer
indexableValuesBuffer
To unpack these buffers correctly, reimplement the class methods:
namedValues:
indexableValues:
namedValues:indexableValues:
By default, namedValuesBuffer returns self; new client objects are faulted directly into the named instance variable slots. Override this to supply either a different object of the same type, or an instance of GbsBuffer (a subclass of Array) of the required size.
By default, indexableValuesBuffer returns self. Override this to return an indexable buffer of the appropriate size.
The buffers you define in these methods are used during faulting. They are subsequently unpacked by the faulted object according to its implementation of the unpacking methods listed above.
Implement the unpacking methods to obtain the desired client representation by performing arbitrary computation on the buffer contents. Use the message namedValues:indexableValues: for cases in which computation must operate on indexable and named values together.
NOTE
The methods namedValuesBuffer and namedValues: are a pair; so are indexableValuesBuffer and indexableValues:. To avoid replication errors, if you override one, you must also override the other.
You can also override the messages indexableValueAt:put: and namedValueAt:put: to process the values of the indexable and named slots of the object. For example, class Set might implement the former as:
Set >> indexableValueAt: index put: aValue
self add: aValue
The method simply adds the element to the Set rather than assigning it to a specific slot.
NOTE
To avoid generating a “The current server didn’t complete” error, if you override namedValues: or indexableValues:, make sure you do not send messages to any stubs that would require a remote object to be faulted. Doing so causes an error as faulting is attempted while flushing. Adjust the replicationSpec and faultPolicy of the object to ensure that stubs won’t exist for special flush operations.
You can override two other messages to control faulting initialization and postprocessing: preFault and postFault.
Implement preFault to initialize a newly created object prior to faulting its named and indexable values.
OrderedCollection >> preFault
"Initialize <firstIndex> and <lastIndex> prior to
adding elements."
self setIndices
The method indexableValueAt:put: for OrderedCollection has an implementation similar to Set to add the indexable objects. As another example, a specialized type of SortedCollection could use preFault to assign the sortBlock so that additions to the collection would be sorted properly during faulting.
Implement postFault to do any necessary postprocessing. For example, if the methods used to add to an OrderedCollection also marked the object dirty, the postprocessing could remove dirty-marking: by definition, faulting never results in a dirty object:
OrderedCollection >> postFault
"Additions to the OrderedCollection are due to the faulting
mechanisms and should not result in a dirty object."
self markNotDirty
Modifying Instance Variables During Flushing
To provide an arbitrary mapping of objects from the client to the server you can implement two class methods called namedValues and indexableValues.
namedValues
Implement this to return a copy of the object being stored or an instance of GbsBuffer sized to match the number of named instance variables in the client object. The store operations then access this buffer for storing in the server.
indexableValues
Implement this to return a list of the indexable instance variables in the client object. The store operations then access this list for storing in the server.
Implementations of namedValues must return an object with the appropriate number of named instance variable slots. In Example 3.1, a clone of the positionable stream is returned that increments the position instance variable by 1 as needed when mapped into the server:
Example 3.1
PositionableStream>>namedValues
| aClone |
aClone := self copy.
aClone instVarAt: 1 put: self contents.
aClone instVarAt: 2 put: position + 1.
^aClone
An alternative might return an instance of GbsBuffer (a subclass of Array) of the appropriate size. (A special buffer class is necessary to distinguish between trying to store an array and trying to store the named values of an object residing in a buffer.)
The default implementation of namedValues is to return self. In this case, the instance variables are processed directly from the object being stored, eliminating the need for a temporary array.
Implementations of indexableValues must return an indexable collection containing a sequential list of the elements in the collection. In Example 3.2, for class Set, an Array is returned, because the indexable fields of a Smalltalk set are a sparse list of the actual elements.
Example 3.2
Set>>indexableValues
| values index |
values := Array new: self size.
index := 1.
self elementsDo: [:each |
values at: index put: each.
index := index + 1].
^values
The default implementation of indexableValues is to return self. In this case, the indexable slots are processed directly from the object being stored, eliminating the need for a temporary array.
You can also override the messages indexableValueAt: and namedValueAt: to return processed values rather than the actual values in the indexable and named slots of the object. For example, OrderedCollection might implement indexableValueAt: as:
OrderedCollection>indexableValueAt: index
^self at: index
This lets OrderedCollection control for the fact that its underlying indexable slots are being managed by the firstIndex and lastIndex instance variables—that is, the first actual indexable slot of the object may not necessarily be the first logical element.
In conjunction with these two methods, you might need to reimplement the messages indexableSize and namedSize as well. For example, to match the implementation of indexableValueAt:above, OrderedCollection would have to implement indexableSize as shown below; otherwise, the object storage mechanisms would try to iterate over the entire list of indexable slots rather than those controlled by firstIndex and lastIndex:
indexableSize
^self size
Mapping Classes With Different Formats
You can create a class in GemStone that maps to a client Smalltalk class with a different format—for example, a format of bytes on the client but pointers in the server. To do so, reimplement the class method gsObjImpl in the client Smalltalk to return a value specifying the GemStone implementation.
A gsObjImpl method must return a SmallInteger representing the GemStone class format. The following formats are valid:
Symbolic names for these values are stored in the pool dictionary SpecialGemStoneObjects.
Limits on Replication
Replicating blocks and collections with instance variables can present special problems, discussed below.
Replicating Client Smalltalk BlockClosures
Forwarders are especially well-suited for managing large collections that reside in the object server. Collections are commonly sent messages that have blocks as arguments. When the collection is represented in client Smalltalk by a forwarder, these argument blocks are replicated in GemStone and executed in the server.
When a GemStone replicate for a client Smalltalk block is needed, GemBuilder sends the block to GemStone Smalltalk for recompilation and execution. If a block is used more than once, GemBuilder saves a reference to the replicated block to avoid redundant compilations.
For example, consider the use of select: to retrieve elements from a collection of Employees:
| fredEmps |
fredEmps := myEmployees select:
[ :anEmployee | (anEmployee name) = 'Fred' ].
If myEmployees is a forwarder to a collection residing in the object server, then GemBuilder sends the parameter block’s source code:
[ :anEmployee | (anEmployee name) = 'Fred' ].
to GemStone to be compiled and executed.
Replication of client Smalltalk blocks to GemStone Smalltalk is subject to certain limitations. When block replication violates one of these limitations, GemBuilder issues an error indicating that the attempted block replication has failed.
To avoid these limitations, consider using block callbacks instead. Block callbacks are discussed starting here.
You can disable block replication completely using GemBuilder’s configuration parameter blockReplicationEnabled. Block replication is enabled by default. Set this parameter to false to disable it, and GemBuilder raises an exception when block replication is attempted. This can be useful for determining if your application depends on block replication.
Image-stripping Limitations
Block replication relies on the client Smalltalk compiler and decompiler; if they’ve been removed from a deployed runtime environment, blocks cannot be replicated.
1. Leave the compiler and decompiler in the image. For example, the VisualWorks Image Maker tool offers a “Remove Compiler” option which you can deselect to leave the compiler and decompiler in the image.
2. Do not use block replication. Usually this requires implementing a cover method for the block in a GemStone method, and sending that message instead. For instance:
aForwarder select: [ :name | name = #Fred ]
aForwarder selectNameEquals: #Fred
...and in GemStone, selectNameEquals: is implemented as:
selectNameEquals: aName
^self select: [ :name | name = aName ]
When the block is encoded entirely in GemStone in this way, you can further optimize its operation by taking advantage of indexes and use an optimized selection block, as described in the GemStone Programming Guide.
Temporary Variable Reference Restrictions
A block is replicated in the form of its source code, without its surrounding context. Therefore, values drawn from outside the block’s own scope cannot be relied upon to exist in both the client Smalltalk and in GemStone. Replication is not supported for blocks that reference instance variables, class variables, method arguments, or temporary variables declared external to the block’s scope.
An exception is allowed in the case of global references, such as class names:
In the case of global variables containing data, it is the programmer’s responsibility to ensure that the global identifier represents compatible values in both contexts.
Temporary variable reference restrictions disallow the following, because “tempName” is declared outside the block’s scope:
| namedEmps tempName |
tempName := 'Fred'.
namedEmps := myEmployees select:
[ :anEmployee | (anEmployee name) = tempName ].
As a workaround, implement a new Employees method in GemStone Smalltalk named select:with: that evaluates a two-argument block, in which the extra block argument is passed in as the with: parameter. For example:
select: aBlock with: extraArg
|result|
result := self speciesForSelect new.
self keysAndValuesDo: [ :aKey :aValue |
(aBlock value: aValue value: extraArg)
ifTrue: [result at: aKey put: aValue]
].
^ result.
You can then rewrite the application code to pass its temporary as the argument to the with: parameter without violating the scope of the block:
| namedEmps tempName |
tempName := 'Fred'.
namedEmps := myEmployees
select: [:anEmployee :extraArg |
(anEmployee name) = extraArg ]
with: tempName.
Restriction on References to self or super
References to self and super are also context-sensitive and, therefore, disallowed:
For example, the following code cannot be forwarded to GemStone because the parameter block contains a reference to self:
myDict at:#key ifAbsent:[ self ]
References to self or super in forwarded code must occur outside the scope of the replicated block, where you can be sure of the context within which they occur. For example, you can rewrite the above code to return a result code, which can then be evaluated in the calling context, outside the scope of the replicated block:
result := myDict at:#key ifAbsent:[#absent].
result = #absent ifTrue: [ self ]
Explicit Return Restriction
Because a block is replicated without its surrounding context, a return statement has no surrounding context to which to return. Therefore:
result := myDict at:#key ifAbsent:[ ^nil ]
is disallowed. The statement can be recoded to perform its return within the calling context:
result := myDict at:#key ifAbsent:[#absent].
result = #absent ifTrue: [ ^nil ]
Replicating GemStone Blocks in Client Smalltalk
Also supported, though less commonly used, is the replication of GemStone blocks in client Smalltalk. Similar restrictions apply with regard to external references and the need for compiler/decompiler support. Blocks most frequently passed from the server to the client are the sort blocks that accompany instances of SortedCollection and its subclasses. Sort blocks rarely have occasion to violate replicated block restrictions.
If restrictions hamper you, consider using block callbacks instead.
Block Callbacks
Block callbacks provide an alternate mechanism for representing a client block in GemStone that avoids the limitations of block replication by calling back into the client Smalltalk to evaluate the block.
Block callbacks have the following advantages over block replication:
- Block callbacks don’t require a compiler or decompiler.
- Block callbacks don’t suffer the context limitations of block replication. The block can reference self, super, instance variables, and non-local temporaries; it can also perform explicit returns. For example, the following expression works correctly as a block callback, but fails if you try to replicate the block:
aForwarder at: aKey ifAbsent: [ ^nil ] asBlockCallback
Block callbacks have the following disadvantages:
- A block that is evaluated many times in GemStone will perform poorly as a block callback. For example, the following expression sends a message to a client forwarder for each element of the collection represented by aForwarder:
aForwarder select: [ :e | e isNil ] asBlockCallback
You can determine whether, by default, blocks are replicated or call back to the client using GemBuilder’s configuration parameter blockReplicationPolicy. Legal values #replicate and #callback. A value of #replicate causes a client block to be stored in GemStone as a GemStone block. A value of #callback causes a client block to be stored in GemStone as a client forwarder, so that sending value to the block in GemStone causes value to be forwarded to the client block; the result of that block evaluation is then passed back to the GemStone context that invoked the block.
To ensure a specific replication policy for a given block, use the methods asBlockCallback or asBlockReplicate. Send asBlockCallback to ensure that the block always executes in the client, regardless of the default block replication policy set by the configuration parameter. Likewise, send asBlockReplicate to ensure that the block is executed local to the context that invokes it (either in GemStone or in the client).For example:
dictionaryForwarder
at: #X
ifAbsent: [ ^nil ] asBlockCallback
collectionForwarder do: [ :e | e check ] asBlockReplicate
Replicating Collections with Instance Variables
If you create a subclass of a Collection and give it instance variables, you must reimplement the copyEmpty: method to ensure that added instance variables are included in the copy operation. Failure to reimplement copyEmpty: results in data loss.
For example, consider a Collection subclass called MyCollection that defines the additional instance variable name, with methods name and name: that retrieve and assign its value, respectively. MyCollection might reimplement copyEmpty: like this:
MyCollection >> copyEmpty: size
^(super copyEmpty: size) name: name
This reimplementation of copyEmpty: preserves the copying behavior of the superclass and assures that the added instance variable is also copied.
3.5 Precedence of Replication Controls
Certain replication controls can appear to contradict each other. The rules of precedence are:
1. If the class methods instVarMap (for replicates) or instancesAreForwarders (for forwarders) are implemented, they take precedence over all others and are always respected.
2. Otherwise, if the class method replicationSpec is implemented, or if an application sends replicationSpecSet: to switch among several replication specs, those replication specs take precedence.
In other words, if a class implements a replication spec, but it also implements instancesAreForwarders to return true, then instances of that class will be forwarders and the replication spec will be ignored.
Or, if a class implements both instVarMap and replicationSpec, the instVarMap determines which instance variables will be visible to the replication spec.
3. In the absence of a replication spec, the instance method faultToLevel:, if called, is respected for replicates. Forwarders, of course, do not fault.
4. For classes that use no other mechanism, the configuration parameters faultLevelLnk and faultLevelRpc are respected.
3.6 Evaluating Smalltalk Code on the GemStone server
In addition to sending messages to forwarders, GemBuilder provides mechanisms to execute ad-hoc Smalltalk code on the server.
Using the development environment Workspace, you can type in and select Smalltalk code and use the menu option “GS-Do it”, “GS-Inspect it” or “GS-Print it” to execute the selected text on the GemStone server, and return a replicate of the results.
You can also do this on the client by sending the string to a session for execution. The expression:
aGbsSession evaluate: aString
when executed on the client, tells GemBuilder to have the server compile and execute the GemStone Smalltalk code contained in aString, and answer a client replicate of the result of that execution. If, rather than a replicate, you would like the result as a forwarder, use the expression
aGbsSession fwevaluate: aString
The code in aString may be any arbitrary GemStone Smalltalk code that would be a valid method body (see Appendix A of the GemStone Programming Guide for GemStone Smalltalk syntax), with the exceptions that the code:
- cannot take any arguments
- must not refer to the variables self or super
- must not refer to any instance variable of any class
Example 3.3 shows how to use evaluate: to execute code.
Example 3.3
resultReplicate := GBSM currentSession
evaluate: '
| result |
result := Array new: 3.
result
at: 1 put: ''Pear'';
at: 2 put: #unripe;
at: 3 put: 42.
^ result'
You can avoid some of these restrictions by passing in a context object using:
aGbsSession evaluate: aString context: aServerObject
aGbsSession fwevaluate: aString context: aServerObject
The context argument, aServerObject, can be any replicate of or forwarder to a GemStone server object. If the code in aString refers to the variables self or super, these will be bound to the context object. The code in aString can also refer to any instance variables of the context object.
aGbsSession
evaluate: 'self at: 2 put: #ripe'
context: resultReplicate.
The advantage of the evaluate: family of messages is that they allow you to execute arbitrary ad-hoc code on the server without previously defining a method.
However, this isn't always the best way to execute server code. The evaluate: messages invoke the GemStone Smalltalk compiler upon each execution, and so have extra overhead. Also, the inability to pass arguments rules out the evaluate: messages for some uses.
Message sends through forwarders are the most common means of initiating execution of GemStone Smalltalk code on the server. However, a message passed through a forwarder will fail if the server object that receives the message does not understand that message. Forwarder sends require previous definition of an appropriate GemStone method on the server.
The two forms of execution complement each other. The evaluate: messages do not require prior method definition, but cannot take arguments. Forwarder sends require prior method definition, but can take arguments.
3.7 Converting Between Forms
A variety of messages exist to convert between delegates, forwarders, replicates, stubs, and unconnected client objects. The following tables list the results of sending any of several conversion messages to these objects.
A delegate is an instance of GbxDelegate. Delegates are used internally by GemBuilder. An application doesn’t normally need to use delegates directly, but you may see them when debugging. We recommend against using delegate protocol, as in Table 3.1, in customer applications.
NOTE
To avoid unpredictable consequences and possible errors, do not use the expressions described as producing undefined results.
|
copies associated server object and returns a replicate of the copy |
|
|
the associated delegate |
|
|
the associated delegate |
|