9. Performance Tuning
This chapter discusses ways that you can tune your GemBuilder application to optimize performance and minimize maintenance overhead.
See Chapter 10, “GemBuilder Configuration Parameters” for GemBuilder configuration parameters that can used to tune performance.
For further information, see the Programming Guide for your GemStone/S server for a discussion on how to optimize GemStone Smalltalk code for faster performance. That manual explains how to cluster objects for fast retrieval, how to profile your code to determine where to optimize, and discusses optimal cache sizes to improve performance.
9.1 Profiling
Before you can optimize the performance of your application, you must find out where most of the execution time is being spent. There are client Smalltalk tools available for profiling client code. GemStone also has a profiling tool in the class ProfMonitor. This class allows you to sample the methods that are executed in a given block of code and to estimate the percentage of total execution time represented by each method, within GemStone server execution. See the chapter on performance in the GemStone Programming Guide for details.
Profiling Client Smalltalk Execution
GemBuilder can be configured to collect statistics describing the performance of its internal operation. These statistics are archived to a file (a statistics archive file), which can be viewed by GemTalk’s VSD (Visual Stat Display) tool (see The VSD tool). Statistics tracking introduces minimal overhead into GBS. A VisualWorks process named “GBS Stat Monitor” samples and archives the statistics at a regular, configurable time interval.
GBS provides several types of statistics:
- Session manager statistics.
- Statistics for each logged in session.
- Object memory statistics for VisualWorks.
- Cache inventory statistics, providing the count and size of objects in the cache.
To enable the tracking of all types of GBS statistics in an image, and start the statistics monitor, execute the following:
GBSM statsEnabled: true
It can be disabled and the monitor turned off by passing false to the above method.
You may also choose to monitor the Main statistics, excluding the cache inventory. To monitor GbsSessionManager, GbsSession, and ObjectMemory statistics only, and to start the statistics monitor, execute:
GBSM mainStatsEnabled: true.
GBSM statMonitorRunning: true.
Unlike the all-in-one “statsEnabled:” method, this method doesn't start the statistics monitor, so you need to explicitly start the monitor.
The default sample interval for the above methods is 2 seconds (2000 milliseconds). To specific another statistics archiving interval in milliseconds, execute:
GBSM statSampleInterval: milliseconds
Main Statistics
The session manager statistics are:
The statistics associated with each logged in session are:
The statistics associated with VisualWorks object memory are:
Cache Inventory Statistics
GBS provides cache inventory statistics, which show the number of instances of, and bytes consumed by, each class of object found in the clientMap (formerly the stObjectCache). When viewing statistics in VSD, each class will be listed in the process list, with the cache statistics numInstances and gbsBytesCached.
To enable cache inventory statistics without enabling main statistics, execute:
GBSM cacheStatsEnabled: true
GBSM statMonitorRunning: true
Cache inventory statistics are more expensive to sample and archive than the main GBS statistics. Because of this, cache statistics are not sampled and archived every time the statistics monitor performs sampling and archiving of the main statistics. By default, the cache statistics are sampled and archived every 5th time. This value is configurable by sending:
GBSM cacheSampleIntervalMultiplier: anInteger
This value times statSampleInterval is the interval between two cache statistics samples. For example, with the default cacheSampleIntervalMultiplier of 5 and the default statSampleInterval of 2000 milliseconds, the cache statistics will be sampled and archived every 10000 milliseconds (or once every 10 seconds). A cacheSampleIntervalMultiplier of 1 would mean that cache statistics will be sampled and archived every time the main statistics are sampled.
The VSD tool
The Visual Statistics Display tool, VSD, is provided with the GemStone server product, and can be found in the directory $GEMSTONE/bin/vsd.
VSD does not require the GemStone server; you can download and install VSD onto another machine to perform the analysis. The latest versions of VSD for all supported platforms are provided on the GemTalk website:
https://gemtalksystems.com/products/vsd/
To view one or more GBS statistics files, invoke vsd with the statistic files as arguments, or load the statistics file after starting vsd. See the VSD User’s Guide for more information on installing and using VSD.
9.2 Selecting the Locus of Control
By default, GemBuilder executes code in the client Smalltalk. Objects are stored in GemStone for persistence and sharing but are replicated in the client Smalltalk for manipulation. In general, this policy works well. There are times, however, when it is preferable or required to execute in GemStone.
One motivation for preferring execution in GemStone is to improve performance. Certain functions can be performed much more efficiently in GemStone. The following section discusses the trade-offs between client Smalltalk and server Smalltalk execution and how to choose one space over the other.
Beyond optimization, some functions can be performed only in GemStone. GemStone’s System class, for example, cannot be replicated in the client Smalltalk; messages to System have to be sent in GemStone.
Locus of Execution
This section centers on controlling the locus of execution—in other words, determining whether certain parts of an application should execute in the client Smalltalk or in GemStone. Subsequent sections discuss other ways of tuning to increase execution speed.
Client Smalltalk and GemStone Smalltalk are very similar languages. Using GemBuilder, it is easy to define behavior in either client Smalltalk or GemStone to accomplish the same task. There are, however, performance implications in the placement of the execution. This section discusses several factors to weigh when choosing the space in which to execute methods.
Relative Platform Speeds
One consideration when choosing the execution platform is the relative speed of the client Smalltalk and the server Smalltalk execution environments. Your client Smalltalk may run faster than GemStone on the same machine. GemStone’s database management functions and its ability to handle very large data sets add some overhead that the client Smalltalk environment doesn’t have.
Cost of Data Management
Execution cannot complete until all objects required have been brought into the object space. When executing in the client Smalltalk, this means that all GemStone server objects required by the message must be faulted from GemStone. When executing in GemStone, this means that dirty replicates must be flushed from the client Smalltalk. In general, it is impossible to tell exactly which objects will be required by a message send, so GemBuilder flushes all dirty replicates before a GemStone message send and faults all dirty GemStone server objects after the send.
Clearly, data movement can be expensive. Although the client Smalltalk environment might be more efficient for some messages, faulting the object into the client Smalltalk might overwhelm the savings. If the objects are all already there, however, or if the objects will be reused for other messages, then the movement may be justified.
For example, consider searching a set of employees for a specific employee, giving her a raise, and then moving on to another unrelated operation. Although a brute force search may be faster in your client Smalltalk, the cost of moving the data to the client may exceed the savings. The search should probably be done in GemStone.
However, if additional operations are going to be done on the employee set, the cost of moving data is amortized and, as the number of operations increases, becomes less than the potential savings.
GemStone Optimization
Some optimizations are possible only using GemStone server execution. In particular, repository searching and sorting can be done much more quickly on the GemStone server than in your client Smalltalk as data sets become large.
If you will be doing frequent searches of data sets such as the employee set in the previous example, using an index on the server Smalltalk set will speed execution.
The GemStone Programming Guide provides a complete discussion of indexes and optimized queries.
9.3 Replication Tuning
The faulting of GemStone server objects into the client Smalltalk is described in Chapter 3. As described there, a GemStone server object has a replicate in the client Smalltalk created for itself, and, recursively, for objects it contains to a certain level, at which point stubs instead of replicates are created.
Faulting objects to the proper number of levels can noticeably improve performance. Clearly, there is a cost for faulting objects into the client Smalltalk. This is made up of communication cost with GemStone, object accessing in GemStone, object creation and initialization in the client Smalltalk, and increased virtual machine requirements in the client Smalltalk as the number of objects grows. For this reason, you should try to minimize faulting and fault in to the client only those objects that will actually be used in the client.
On the other hand, inadequate faulting also has its penalties. Communication overhead is important. When fetching an employee object, it is wasteful to stub the name and then immediately fetch the name from GemStone. It is better to avoid creating the stub and then invoking the fault mechanism when sending it a message.
Controlling the Fault Level
By default, two levels of objects are faulted with the linked version of GemBuilder, and four levels are faulted for the RPC version. This reflects the cost of remote procedure calls and the judgment that it is better to risk fetching unneeded objects to avoid extra calls to GemStone.
It is possible to tune the levels of stubbing to a more optimal level with a knowledge of the application being programmed. You can set the configuration parameters faultLevelRpc and faultLevelLnk to a SmallInteger indicating the number of levels to replicate when updating an object from GemStone to the client Smalltalk. A level of 2 means to replicate the object and each object it references, stubbing objects beyond that level. A level of 0 indicates no limit; that is, entering 0 prevents any stubs from being created. The default for the linked version is 2; the default for the RPC version is 4. To examine or change this parameter, in the GemStone Launcher choose Browse > Settings and select the Replication tab in the resulting Settings Browser.
NOTE
Take care when using a level of 0 to control replication. GemStone can store more objects than can be replicated in a client Smalltalk object space.
Preventing Transient Stubs
If the default faultLevelLnk or faultLevelRpc is the only mechanism used to control fault levels, it is possible to create large numbers of stubs that are immediately unstubbed.
To prevent stubbing on a class basis, reimplement the replicationSpec class method for that class. For details, see Replication Specifications.
Setting the Traversal Buffer Size
The traversal buffer is an internal buffer that GemBuilder uses when retrieving objects from GemStone. The larger the traversal buffer size, the more information GemBuilder is able to transfer in a single network call to GemStone. To change its value, send the message
GbsConfiguration current traversalBufferSize: smallIntegerBytes.
You can also change this value by using the Settings Browser: from the GemStone Launcher, select the Settings icon on the toolbar, or choose Tools > Settings and select the Server Communications category in the resulting Settings Browser.
This does not affect currently logged-in sessions; it takes effect for sessions that login following the change.
9.4 Optimizing Space Management
In normal use of GemBuilder, objects are faulted from GemStone to the client Smalltalk on demand. In many ways, however, this is a one-way street, and the client Smalltalk object space can only grow. Advantages can be gained if client Smalltalk replicates can be discarded when they are no longer needed. A reduced number of objects on the client reduces the load on the virtual machine, garbage collection, and various other functions.
Measures you can take to control the size of the client Smalltalk object cache include explicit stubbing, using forwarders, and not caching certain objects.
Explicit Stubbing
If the application knows that a replicate is not going to be used for a period of time, the space taken by that object can be reclaimed by sending it the message stubYourself. More importantly, any objects it references become candidates for garbage collection in your client Smalltalk.
Consider having replicated a set of employees. After faulting in the set and the objects transitively referenced from that set, the objects in the client Smalltalk look something like this.
Figure 9.1 Employee Set Faulted into the Client Smalltalk
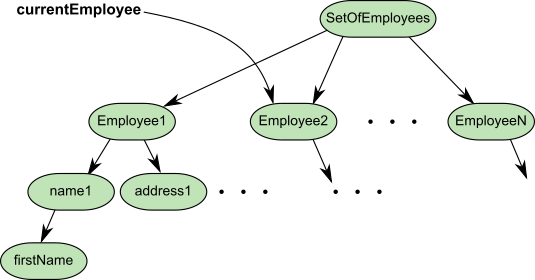
Clearly, there can be a large number of objects referenced transitively from the employee set. If the application’s focus of interest changes from the set to, say, a specific employee, it may make sense to free the object space used by the employee set.
In this example, one solution is to send stubYourself to the setOfEmployees. All employees, except those referenced separately from the set, become candidates for garbage collection.
Of course, if the application will be referencing the setOfEmployees again in the near future, the advantage gained by stubbing could be offset by the increased cost of faulting later on.
If you send stubYourself to an object within a method, be careful not to read instance variables of the unstubbed class later in the same method, since the stub will not have these variables and you may observe incorrect nil values.
Using Forwarders
Another solution is to declare the setOfEmployees as a forwarder. For more information, see Forwarders.
9.5 Using Primitives
Sometimes there is an advantage to dropping out of Smalltalk programming and writing methods in a lower-level language such as C. Such methods are called primitives in Smalltalk; GemStone refers to them as user actions and C Callouts. User Actions allow you to access Smalltalk objects using C code, while C Callouts allow you to invoke C libraries using C data types.
There are serious concerns when doing this. In general, such applications will be less portable and less maintainable. However, when used judiciously, there can be significant performance benefits.
In general, profile your code and find those methods that are heavily used to be candidates for primitives or user actions. The trick to proper use of primitives or user actions is to create as few as possible. Excess primitives or user actions make the system more difficult to understand and place a heavy burden on the maintainer.
For a description about adding primitives to your client Smalltalk, see the vendor’s documentation. C Callouts are described in the Programming Guide for your GemStone/S server; User Actions are described in the GemBuilder for C manual.
9.6 Multiprocess Applications
Some applications support multiple Smalltalk processes running concurrently in a single image. In addition, some applications enter into a multiprocess state occasionally when they make use of signalling and notification. Multiprocess GemBuilder applications must exercise some precautions in order to preserve expected behavior and data integrity among their concurrent processes.
Blocking and Nonblocking Protocol
In a linked GemBuilder session, GemStone operations execute synchronously: the entire client Smalltalk VM must wait for a GemStone operation to complete before proceeding with the execution process that called it. Synchronous operation is known in GemBuilder as blocking protocol.
An RPC GemBuilder session can support asynchronous operation: nonblocking protocol. When the configuration parameter blockingProtocolRpc is false (the default setting in RPC sessions), client Smalltalk processes (other than the process interacting with GemStone) can proceed with execution during GemStone operations. A session, however, is permitted only one outstanding GemStone operation at a time.
When blockingProtocolRpc is true, behavior is the same as in a linked session: the entire client Smalltalk VM must wait for a GemStone call to return before proceeding.
One Process per Session
Applications that limit themselves to one client Smalltalk process per GemStone session are relatively easy to design because each process has its own view of the repository. Each process can rely on GemStone to coordinate its modifications to shared objects with modifications performed by other processes, each of which has its own session and own view of the repository. If at all possible, try to limit your application to one process per GemStone session.
Multiple Processes per Session
Applications that have multiple processes running against a single GemStone session must take additional precautions.
You may not have designed your application to run multiple processes with a single GemStone session. However, if your application uses signals and notifiers, chances are it is occasionally running two processes against a single GemStone session. Methods that create concurrent processes include:
GbsSession >> notificationAction:
GbsSession >> gemSignalAction:
GbsSession >> signaledAbortAction:
When the specified event occurs, the block you supply to these methods runs in a separate process. Unless your main execution process is idle when these events occur, you need to take the same precautions as any other application running multiple processes against a single session.
Applications that have multiple processes running against a single GemStone session should take these additional precautions:
GemBuilder provides a method, GbsSession>>critical: aBlock, that evaluates the supplied block under the protection of a semaphore that is unique to that session. The best approach to creating an application that must support more than one process interacting with a single GemStone session is to organize its logical transactions into short operations that can be performed entirely within the protection of GbsSession>>critical:. All of that session’s commits, aborts, executes, forwarder sends, flushes and faults should be performed within GbsSession>>critical: blocks.
For example, a block that implements a writing transaction will typically start with an abort, make object modifications, and then finish with a commit. A block that implements a reading transaction might start with an abort, perhaps perform a GemStone query, and then maybe display the result in the user interface.
Coordinating Transaction Boundaries
Multiple processes need to be in agreement before a commit or abort occurs. For example, suppose two processes share a single GemStone session. If one process is in the process of modifying a set of persistent objects and a second process performs a commit, the committed state of the repository will contain a logically inconsistent state of that set of objects.
The application must coordinate transaction boundaries. One way to do this is to make one process the transaction controller for a session, and require that all other processes sharing that session request that process for a transaction state change. The controller process can then be blocked from performing that change until all other processes using that session have relinquished control by means of some semaphore protocol.
Coordinating Flushing
GemBuilder’s transparency mechanism flushes dirty objects to GemStone whenever a commit, abort, GemStone execution or forwarder send occurs. Whenever a process modifies persistent objects, it must protect against other processes performing operations that trigger flushing of dirty objects to GemStone. The risks are that a flush may catch a logically inconsistent state of a single object, or might cause GemBuilder to mark an object “not dirty” without really flushing it.
To control when flushing occurs, perform update operations within a block passed to GbsSession>>critical:.
Coordinating Faulting
If two processes send a message to a stub at roughly the same time, one of the processes can receive an incomplete view of the contents of the object. This results in doesNotUnderstand errors which cannot be explained by looking at them under a debugger, because by the time it is visible in the debugger, the object has been completely initialized. Unstubbing conflicts can be avoided by encapsulating potential unstubbing operations within the protection of a GbsSession>>critical: block.