1. Administration of t he GemStone/S Environment 
This manual provides information that is useful for configuring and administering a GemStone/S 64 Bit™ installation. This includes configuring GemStone installations, both new systems and systems that have grown or whose requirements have changed; how to keep a GemStone system running smoothly, including recovering from problems and troubleshooting; and information helpful in tuning each of the subsystems that allow GemStone to operate efficiently and seamlessly.
This chapter provides some basic information about the parts of a GemStone installation, and an overview of the Administration process.
The details of installing GemStone software, and upgrading from earlier versions, is described in detail in the Installation Guide, which are platform-specific. Refer to these guides for information on tuning your OS parameters for most efficient use of GemStone.
1.1 Basic GemStone/S 64 Bit Architecture
Figure 1.1 shows the basic GemStone/S 64 Bit architecture. The GemStone object server can be thought of as having two parts. The server processes consist of the Stone repository monitor and a set of subordinate processes. These processes provide resources to individual Gem session processes, which are servers for application clients.
While in this simple configuration, the remote nodes hold only the Application Clients, there are further options to distribute components over multiple nodes, described later in this manual.

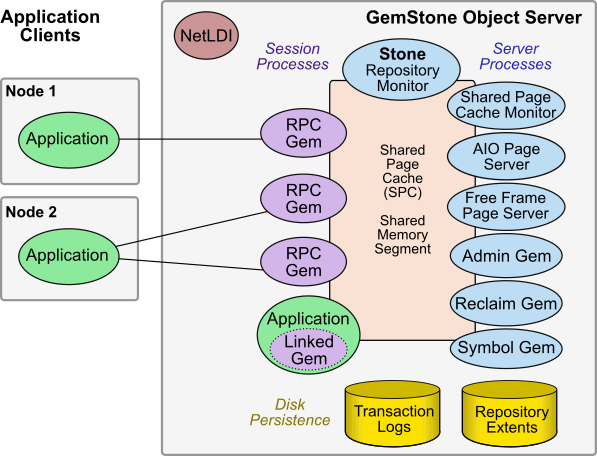
Server Processes
- The Stone repository monitor process acts as a resource coordinator. It synchronizes critical repository activities and ensures repository consistency.
- The shared page cache (SPC) is a shared memory segment that holds the pages on which data and metainformation are stored. Pages are read into frames in the cache. Pages are read from and written to the extent files, and used for temporary data. A larger cache provides better performance since it reduces disk I/O; the cache may be large enough to hold all data in the extents.
- The shared page cache monitor process creates and maintains the shared page cache. The monitor balances page allocation among processes, ensuring that a few users or large objects do not monopolize the cache.
- The AIO page server performs asynchronous I/O, in particular to update the extent files based on changes in the shared page cache.
- The Free Frame Page Server helps ensure that there are free frames in the shared page cache so they are available for the Gems to use.
- The Admin Gem performs administrative garbage collection tasks.
- The Reclaim Gem performs reclaim, cleaning up old versions of objects and dead objects, so that the pages can be reused.
- The Symbol Gem is responsible for creating all new Symbols, based on session requests that are managed by the Stone.
Disk-based Persistence
- Objects are stored on disk in one or more extents, which can be files in the file system, data in raw partitions, or a mixture.
- Transaction logs permit recovery of committed data if a system crash occurs, and in full logging mode allows transaction logs to be used with GemStone backups for full recovery of committed transactions in case of disk failure.
Session Processes
1.2 Starting GemStone and Logging In
Stone
A configured GemStone server is started by the startstone command, which starts the Stone repository monitor. The Stone in turn starts the shared page cache monitor and other server processes. The extent files are attached, and a transaction log opened for writing.
The Stone is named; by default, gs64stone. Only one Stone with a given name can run on a particular node.
You may run more than one Stone on a node, as long as names are different and the extent files and transaction logs are in different locations or have different names.
|
Configuring the Stone and other server processes is described in Chapter 2, “Configuring the GemStone Server”. For details on starting the Stone and other server processes, and troubleshooting issues, see Starting the GemStone Server. |
Shared Page Cache
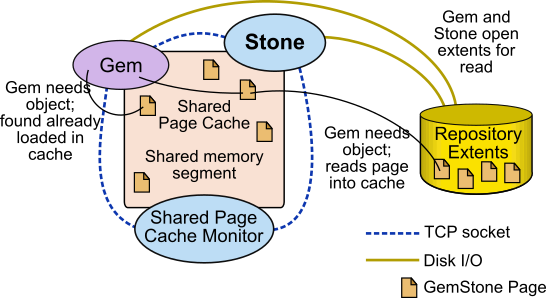
The GemStone shared page cache system has two parts: the shared page cache itself, a shared memory segment; and a monitor process, the shared page cache monitor (shrpcmonitor). Figure 1.2 shows the connections between these and other components on a single node.
The shared page cache resides in a segment of the operating system’s virtual memory that is available to any authorized process. When the Stone or a Gem session process needs to access an object in the repository, it first checks to see whether the page containing that object is already in the cache. If the page is already present, the process reads the object directly from shared memory. If the page is not present, the process reads the page from the disk into the cache, where all of its objects also become available to other processes.
The shared page cache monitor also has a name, which is derived from the name of the Stone repository monitor and the Host Identifier; for instance, gs64stone~d7e2174792b1f787.
Each Stone has a single shared page cache on its own node, and may have remote page caches on other nodes in distributed configurations (discussed in detail in Chapter 5). The Stone spawns the shared page cache monitor automatically during startup, and the shared page cache monitor creates the shared memory region and allocates the semaphores for the system. All sessions that log into this Stone connect to this shared page cache and monitor process.
Shared Cache Size
GemStone performance is almost always improved by making the Shared Page Cache larger, up to a size in which the entire repository can be held in memory.
With a very large cache, it is recommended to run cache warming on startup, so that at least the pages containing the object table (used for lookup) are loaded into the cache. Otherwise, the first access to data will require the pages to be read from disk.
With very large caches on Linux and AIX, you can improve memory use by configuring the cache to use large memory pages; 16MB on AIX, and 2MB and 1GB pages on Linux.
OS memory and Swapping
As described in the Installation Guide, you are likely to need to configure your OS to support a sufficiently large shared memory segment.
Be careful not to make the shared page cache so large that it forces swapping. You should ensure that your system has sufficient RAM to hold the configured shared page cache, with extra space for the other memory requirements.
|
For details on configuring the shared page cache, see Shared Page Cache. |
NetLDI
A NetLDI also must be configured and explicitly started. While there are some cases, in which there are only linked logins, that do not require a NetLDI, most installations will need to start a NetLDI.
Each NetLDI has a name, but may also be referred to by its listening port number. The default name is gs64ldi; by using this name and setting this up in the services database on all your nodes, you can skip the step of specifying the NetLDI.
You may run more than one NetLDI on a node, related to the same GemStone system or an entirely different system, as long as the names and ports are different.
If you are using more than one NetLDI on a particular node, and one of them is running with the default name, use particular care to ensure that all logins contact the correct NetLDI.
|
Setting up the NetLDI is described in Chapter 4, “NetLDI and Interprocess Access”. For details on starting the NetLDI see Starting a NetLDI. |
Logging in Gem Sessions
- the topaz command line tool provided as part of the server
- client Smalltalk applications such as VisualWorks and VA Smalltalk using GBS
- web applications
- other custom GCI application
Client application are configured to load the GCI shared library, provided as a .dll, .dynlib, or .so file, containing the Gem API.
The login commands include, of course, GemStone authorization details. The specification of the Stone and node must be provided, and the location where the Gem process is to be run. The details need to include the name or port of the NetLDI that sets up the login. This information is provided using special NRS (Network Resource String) syntax.
The NetLDI uses that information to fork the Gem process, trigger the startup of any other required server processes, and setup the interprocess communications.
Linked vs. RPC
In a linked login, GCI shared libraries are loaded into the client application (linked topaz, GBS, or another), and Gem is part of that client application. Since the Gem is part of the server, this is only possible on platforms that support the GemStone/S 64 Bit server, i.e., not on Windows.
In an RPC login, the Gem is a separate process from the client application. The two processes may be on the same node or on different nodes, and communicate via remote procedure calls.
Gemservers for Large Configurations
Each Gem is an individual process. Depending on your hardware, there is an limit to the number of processes that you can run before degrading performance. For very large configurations, it may be useful to establish a separate node specifically to run Gem sessions, with a high bandwidth connection between the repository server and the Gem server. The Gems on this gemserver have the performance benefit of a remote shared page cache on this node.
|
Configuring client Gems is described in Chapter 3, “Configuring Gem Session Processes”. For more information on logging in a Gem session, see Starting a GemStone Session. |
NRS (Network Resource String)
GemStone’s proprietary NRS syntax is used to specify the name and location of each part of the GemStone system. These are widely used in utility commands and in login parameters, to specify the location and name of the Stone and NetLDI, and where the other GemStone processes should run.
|
Appendix C, “Network Resource Strings (NRS)” describes NRS strings in detail. |
The most commonly used syntax, as in the examples in this manual, has the form:
!@nodeNameOrId#netldi:netldiNameOrPort!stoneOrGemService
- The “@nodeNameOrId” can be omitted for the local node.
- the “#netldi:netldiNameOrPort” can be omitted if the NetLDI is running with the default name gs64ldi, and the name and port are configured in the services database.
- stoneOrGemService is the name of the running Stone, or gemnetobject or another Gem service. If you omit both node and netldi, you do not need the ! dividers; you can use only stoneOrGemService.
1.3 Authentication and Authorization
GemStone provides several levels of security; UNIX user accounts must have permission and may require authentication; login to GemStone requires a GemStone account and authentication; and objects and access to data and important functions is controlled within GemStone using SecurityPolicies and Privileges. In full logging mode, all commits to the repository are recorded in the transaction logs, which can be analyzed to determine the source of changes; and the system can be configured to log all logins.
GemStone UserIds and login
Logins to GemStone are done as GemStone users, which are instances of UserProfile. UserProfiles have names and passwords that are unrelated to UNIX userIds, although GemStone UserProfiles can be created that correspond to the UNIX account names.
Login authentication can be configured to use UNIX or LDAP, in which case either the names must match, or the UserProfile configured with the mapping. UserProfiles can also be configured with single sign-on using Kerberos, by setting up the appropriate mapping within GemStone.
There are several built-in system accounts, including SystemUser, which is similar to a “root” user, used for upgrades; and DataCurator, the administrative user for tasks such as backups and User administration. Other system accounts are used for garbage collection and symbol creation.
When GemStone UserProfile authentication is controlled by GemStone, there are a number of ways to restrict password choice, require password changes, and disable accounts in cases such as too many failed logins. Internally, passwords are stored only in the encrypted form and there is no facility to decrypt them.
A number of important operation, such as code modification and garbage collection, may be restricted to certain users by using privileges. UserProfile may be granted privileges that allow them to perform these operations.
|
Configuring and Administering Users, Groups, and Privileges in described in Chapter 8, “User Accounts and Security”. |
Authorization to Access Data
Within GemStone, Objects are associated with Security Policies, that allow specific GemStone Users or Groups of users to write, read, or have no access to particular objects. This provides a highly granular way of protecting critical data.
|
How to apply Security Policies to your data is described in the GemStone/S 64 Bit Programming Guide. |
File access and authorization
As a multiuser system, GemStone must allow applications running under different UNIX userIds to create processes that access the repository disk files, while ensuring that the disk files are protected against unauthorized access or modification, both intentional and accidental. This involves managing the permissions for important files and controlling the process owners and groups. Configuring security is described in Chapter 4.
Initial login requests to GemStone connect using SSL (Secure Socket Layer; more specifically, TLS protocol using OpenSSL). For processes on the same machine, communications after the login continue using primarily shared memory. Remote socket connections may be SSL or not, depending on your security requirements.
|
Setting up file permissions and authentication is described in Chapter 4. |
1.4 Transactions and commit records
GemStone maintains a consistent view for each user, and all changes that are made persistent and visible to other users are done within transactions. Transactions are committed to make changes persistent; sessions abort to discard modifications and update the objects in their view with changes made by other users.
|
For more information on transactions and commits, refer to the GemStone/S 64 Bit Programming Guide. |
Object views
On login, each GemStone user acquires a “view” of the objects in the repository. This view is maintained as long as you are using it, even if the objects have been modified by other users. You may make modifications to the objects in your view, or create new objects, but these changes are transient unless and until you commit, in which case they become persistent and can be viewed by other users.
Making new objects persistent also requires that they be connected to an existing persistent object. Objects that are not reachable by other objects are subject to garbage collection.
If another user has made a conflicting change, your commit may fail, and you can get a report of the conflicts. You may need to discard the changes. This can be avoided by locking objects prior to modifying them; reduced-conflict classes allows certain kinds of conflict to be automatically resolved.
Session transactional state
Each Gem session is always either “in transaction” or not in transaction (a third state, transactionless, is normally only used for background tasks). Sessions that are in transaction may commit changes; when not in transaction, data may be viewed and objects modified, but these modifications are transient. To make persistent changes, you must begin a transaction, make the changes, and commit successfully.
Sessions that are in a transaction can commit, and any session can abort. When a session commits or aborts, its view is updated with to the most recent view, including any changes by other users.
Commit records
GemStone is designed to accommodate large numbers of users. Each user may have his or her own view of the repository; and each of these views must be maintained as long as they are in use. GemStone maintains these views as Commit Records.
Over time, each of these sessions will commit changes (or abort), at which point the view is no longer required. However, since commit records are sets of changes from a previous view, GemStone must maintain the commit record of the session that has been logged in without commit or abort for the longest time (the oldest commit record) and every intermediate commit record up to the current one.
Commit records are stored in the repository, and a large commit record backlog can use a large amount of repository space. GemStone can signal sessions that are causing a backlog, but applications in multiuser system should be designed to abort or commit and respond to signals to avoid creating backlogs. A long-lasting commit record backlog can fill up all disk space such that the GemStone cannot avoid shutting down.
1.5 Files and Directories
GemStone Installation
The GemStone installation process, as described in the Installation Guide for your platform, describes both how to configure your operating system, and the details of installing GemStone.
After installation, you should have a directory containing the executables, shared libraries, extents and other required or useful files. Not all are required, and they do not need to be located in this shared directory structure.
This directory is referenced by the required environment variable $GEMSTONE.
GemStone shared libraries
Your GemStone installation includes shared library files as well as executables. Access to these shared library files is required for the GemStone executables. In the standard installation of the GemStone software, these shared libraries are located in the $GEMSTONE/lib and $GEMSTONE/lib32 directories.
For installations that do not include a full server, such as remote nodes that are only running client applications, these libraries may be put in a directory other than this standard. See the Installation Guide for more information.
Lock file directory
In addition to the normal installation directory, GemStone requires access to two directories under /opt/gemstone/:
- /opt/gemstone/locks is used for lock files, which among other things provide the names, ports, and other important data used in interprocess communication and reported by gslist.
Under normal circumstances, you should never have to directly access files in this directory. To clear out lock files of processes that exited abnormally, use gslist -c.
- /opt/gemstone/log is the default location for NetLDI log files, if startnetldi does not explicitly specify a location using the -l option.
If /opt/gemstone/ does not exist, GemStone may use /usr/gemstone/ instead.
Alternatively, you can use the environment variable GEMSTONE_GLOBAL_DIR to specify a different location. Since the files in this location control visibility of GemStone processes to one another, all GemStone processes that interact must use the same directory.
Host Identifier
/opt/gemstone/locks (or an alternate directory, as described above) is also the location for a file named gemstone.hostid, which contains the unique host identifier for this host. This file is created by the first GemStone process on that host to require a unique identifier, by reading eight bytes from /dev/random. This unique hostId is used instead of host name or IP address for GemStone inter-process communication, avoiding issues with multi-homed hosts and changing IP address.
You can access the host identifier for the machine hosting the gem session using the method System class >> hostId.
Extents, Tranlogs, and disk space
GemStone data is preserved on disk in one or more extent files. These extents include the classes and objects that make up GemStone, as well as the classes and objects that make up your application. When GemStone is shutdown, these extents provide the complete set of objects that compose the application.
Each time a session commits changes to the repository, the changes are made on pages in the shared page cache, which are eventually written to disk by the AIO page server. A commit also writes a record in the current transaction log, which is immediately written to disk.
While GemStone is running, it periodically makes a checkpoint, at which point all dirty pages in the shared page cache are written to disk, and the root page is updated to a new consistent state. GemStone also writes a checkpoint on an orderly shutdown, and before a backup.
Between checkpoints, updates to the repository are recorded in the transaction logs. If GemStone shuts down unexpectedly, it will startup at the point of the most recent checkpoint in the repository. Changes since that checkpoint are restored from the transaction logs.
Disk Usage for Extents and Transaction Logs
On a single disk, multiple processes writing to both extents and transaction logs will encounter contention, since only one physical write to disk media at a time is possible.
For this reason, if you are not using a SAN or a RAID device that avoids single disk contention, using multiple physical disk drives is recommended for best performance.
Disk configuration
Extents benefit from efficiency of both random access (16 KB repository pages) and sequential access. Sequential access is important for such operations as garbage collection and making or restoring backups, while random access is used for most data I/O. Using RAID devices or striped file systems that cannot efficiently support both random and sequential access may reduce overall performance.
Transaction logs use sequential access exclusively, so the devices can be optimized for that access.
Raw Partitions
Each raw disk partition is like a single large sequential file, with one extent or one transaction log per partition.
In general, placing extents on file systems is as fast as using raw partitions, but transaction logs on raw partitions is likely to yield better performance in an update-intensive application.
Process Log Files
Each GemStone process creates or appends to a log file. These log files include process details, startup configuration information, and messages about any errors that occur. The location and file name of most processes is configurable.
When the process exits, by default some processes leave their log files in place for possible later diagnostic use. Other process types delete log files on a clean exit. A process that exits with a error never deletes its log files.
Note that linked sessions, which do not have an independent Gem process, do not create log files. Log file output is sent to stdout for the client application.
System Clock and GemStone times
The system clock should be set to the correct time. When GemStone opens the repository at startup, it compares the current system time with the recorded checkpoint times as part of a consistency check. A system time earlier than the time at which the last checkpoint was written may be taken as an indication of corrupted data and prevent GemStone from starting.
1.6 Options for Configuring
GemStone is a very flexible system, with many options for configuring details. Almost all of these have defaults; for an “average” system, you will only need to set a few basics: the extent files, transaction logs, and the size of the shared cache.
However, few systems are average. Your application may have larger or smaller amounts of data relative to the number of users, or have a higher commit rate, or a commit rate that varies widely over the course of a day; or your system have particular requirements for reliability, security, or performance; or your system may be distributed over multiple nodes. For example, a nightly batch data archiving process may have very different requirements than a monitoring process that performs frequent small commits.
An application’s configuration is set by assigning values in one or more configuration files. These can be modified, or work in concert with, specific environment variables, arguments to the command-line GemStone utilities, and by executing Smalltalk code that adjusts configuration values or behavior at run-time.
This flexibility permits assigning system-wide values that include both fixed and variable configuration settings, while also allowing various components to override these settings when they have specific needs.
Configuration files
GemStone uses configuration files to hold the specifications for most important configuration details. This includes the names and locations of the extent files, the sizes of the various caches, and many parameters designed for tuning. While there are many parameters, only a few of them are required; in most cases the default is sufficient.
On a new Gemstone system, you must determine the basic configuration before starting. The details on how to establish the configuration are described in Chapter 2, “Configuring the GemStone Server” for the server and Chapter 3, “Configuring Gem Session Processes” for Gems.
GemStone distinguishes between the system configuration file, which applies to the Stone and other system processes, and application configuration files, which apply for Gem sessions (linked and RPC). If all GemStone processes are on a single node, the parameters can all be in a single configuration file. Multiple files can be setup, which apply to different tasks or reside on different nodes.
|
How configuration files are used, and an alphabetic list of parameters, is provided in Appendix A. Specific parameters are discussed throughout this manual. |
Environment variables
There are a number of environment variables that GemStone uses. The most important of these is $GEMSTONE, which is required, and indicates the directory in which GemStone is installed.
Other environment variables provide file locations for configuration files themselves, and other information that is needed before a process is able to read the configuration file.
Finally, some logging and debugging settings are provided as environment variables to allow debugging without affecting other sessions in a multiuser system.
|
Environment variables are listed in Appendix E. Their use is described in various sections to which they apply. |
Utility command arguments
When GemStone is started up, the startup tasks are performed by utility commands, such as startstone to start the stone. These command-line tools accept optional arguments, including such things as process names, port numbers, and log file locations.
|
Utility commands are listed in Appendix B. |
Run-time configurations
Some configuration details are fixed at startup, so making changes requires stopping and and restarting the Stone (which stops all other processes except the NetLDI) or Gem (which means logging out). However, other configuration settings can be modified at runtime by executing Smalltalk code.
Example Configurations
As an example of how the scale of application characteristics affect key GemStone configuration settings, the following table provides some examples of “average” configurations.
While these may be useful in planning, the actual values will be based on your particular hardware and application requirements, and most systems will require additional tuning for optimal performance. GemStone can generate performance statistics, both during development and in production systems. These statistics can be displayed and analyzed using the VSD (Visual Statistics Display) utility to understand bottlenecks and determine both changes that are needed, and to study the effect of configuration and application changes.
GemStone Professional Services can provide expert assistance in establishing your configuration, tuning configurations for performance, and ensuring your configuration can accommodate predicted growth.
|
More information about the individual settings is provided in the detailed instructions for establishing your own configuration, in Chapter 2, “Configuring the GemStone Server”. For details on the specific configuration parameters, see Appendix A. |
1.7 Avoiding risk of Data loss
Protecting data against any risk of loss is a critical part of configuration and application design. Power loss, hardware failure, and disk failures are a risk for any critical system and there are a number of ways to ensure data is protected.
Every unexpected shutdown is different, and the details of how to proceed will depend on the specifics; troubleshooting and recovery is described in more detail in Chapter 4.
GemStone’s elements that protect against data loss include:
- Transaction logs allow automatic recovery after a minor failure, such as a power loss.
- Backups, either programmatic or extent copies, allow you to restore to the time of the backup. Transaction logs in full logging mode allow you to restore transactions.
- Disk level mirroring, or RAID storage, for the transaction logs protects against failure of the disks holding transaction logs.
- hot standbys and warm standbys have secondary systems running in parallel, so they can be made available quickly in case of failure in the primary system.
Recovery vs. Restore
Provided whatever caused the error has been corrected and there is no file damage, a Stone startup following an unexpected shutdown will automatically read the transaction log entries that follow the last checkpoint recorded in the repository, and replay these transaction, recovering the GemStone repository with all committed transactions at the point of shutdown. This is termed “recovery”.
If the extent disk files are damaged, you may need to restore from backup. This involves using a previously-made backup, and replaying all transaction logs that were generated since the backup was made. For this to succeed, you must have a complete set of backup files, and each of the transaction logs that were generated since the time that the backup was started.
Developing a Failover Strategy
The particular strategy to use to protect your data, depends on what the tolerance for data loss is, how soon your application must be available again following an unexpected outage, and the resources available to support a strategy.
Make regular backups and using full transaction logging mode provides the minimal amount of reliability.
Assuming that backups are kept on a separate disk, mirroring the transaction logs (using OS-level tools) avoids the risk of a disk failure causing loss of committed transactions.
A warm or hot standby system can allow the fastest failover, by keeping a secondary system running at all times. In this case, only a minimal amount of further restore is needed before the standby is usable.
|
For more on standbys, see Chapter 12, “Warm and Hot Standbys” |
Verifying strategy
Backups are a form of insurance; they are essential, but may never actually be needed.
While it is not part of everyday operations, it is imperative that you periodically verify that your backup files are correct and usable, and that you know how to perform the recovery or failover operations. When and if a disk failure or other problem occurs, that will be too late to discover you have no recent backups or the backup process has been failing and the backups you have are unusable.
The pressure of a production-down application is not an ideal time for creating your failover or recovery process, nor for the first time executing any failover processes.
1.8 Running a Second Repository
You can run more than one repository on a single node—for example, separate production and development repositories. There are several points to keep in mind:
- Each repository requires its own Stone repository monitor process, extent files, transaction logs, and configuration file. Each Stone will start its own shared page cache monitor and a set of other processes, as described here.
- Multiple Stones that are running the same version of GemStone can share a single installation directory, provided that you create separate repository extents, transaction logs, and configuration files.
- You must give each Stone a unique name at startup. That name is used to identify the server and to maintain separate log files. Users will connect to the repository by specifying the Stone’s name.
- A single NetLDI typically serves all Stones and Gem session processes on a given node, provided both Stones are running the same version. If you are running two different versions of GemStone, you will need two NetLDIs.